
 访问官网
访问官网 Github
Github 论文
论文捕捉波形
论文《捕捉波形:从单个短音频示例学习生成音频》(NeurIPS 2021)的官方 PyTorch 实现
从单个音频输入生成音频
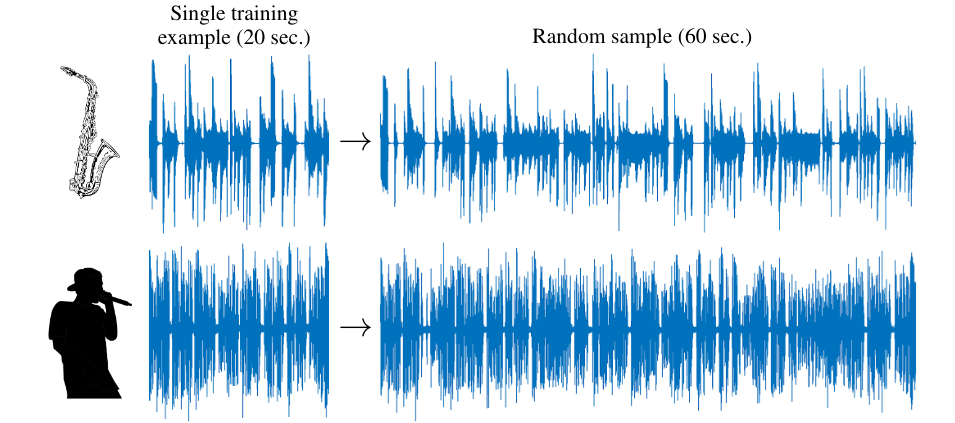
捕捉波形的应用
安装依赖
python -m pip install -r requirements.txt
训练
无条件生成
要进行无条件推理或带宽扩展的训练,只需将音频信号放入 inputs 文件夹并提供其名称。默认扩展名为 .wav,对于具有不同扩展名的文件,请提供带扩展名的名称:
python train_main.py --input_file <输入文件名>
对于语音信号,使用 --speech 标志进行训练:
python train_main.py --input_file <输入文件名> --speech
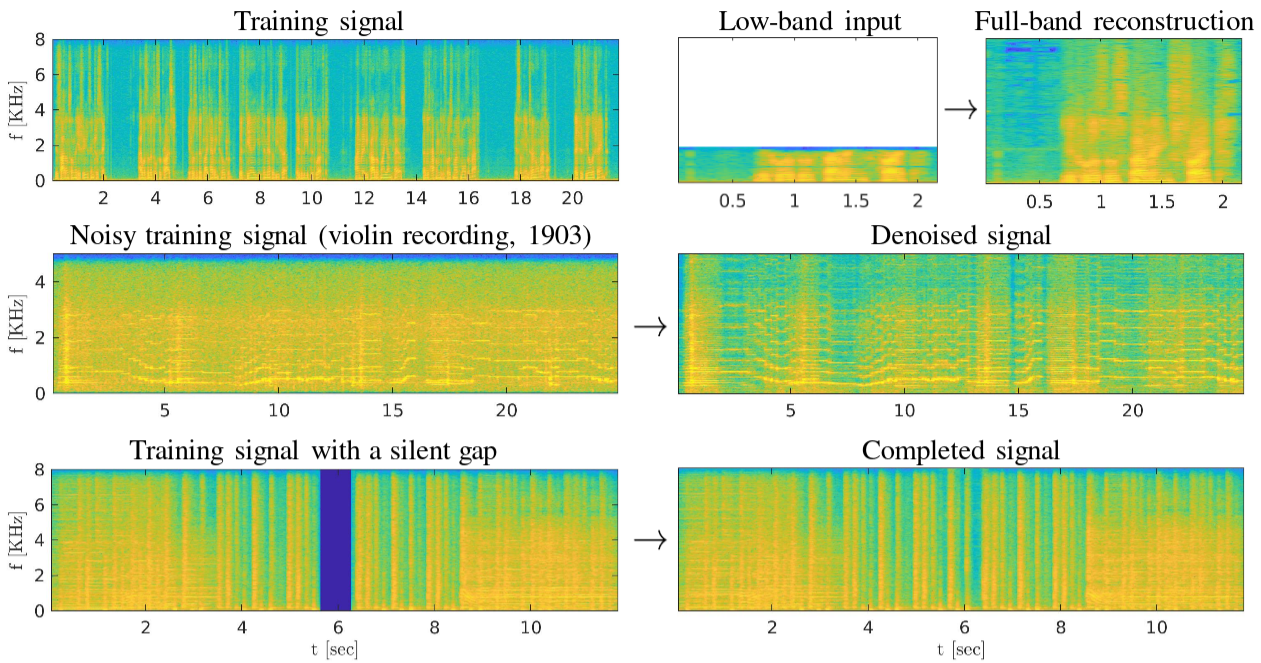
修复
要训练修复任务,将 run_mode 设置为 inpainting,并通过参数 inpainting_indices 提供空洞开始和结束的索引(以样本为单位):
python train_main.py --input_file <输入文件名> --run_mode inpainting --inpainting_indices <空洞开始索引> <空洞结束索引>
通过提供多个索引可以修复多个空洞,例如:
python train_main.py --input_file <输入文件名> --run_mode inpainting --inpainting_indices <空洞1开始索引> <空洞1结束索引> <空洞2开始索引> <空洞2结束索引> ...
去噪
要训练去噪任务,将 run_mode 设置为 denoising:
python train_main.py --input_file <输入文件名> --run_mode denoising
推理
无条件生成
训练后,将在 outputs 文件夹中创建以输入文件命名的目录。要从训练好的模型进行推理,只需运行:
python generate_main.py --input_folder <模型文件夹名称>
这将在模型文件夹内的 GeneratedSignals 中生成一个 30 秒长的信号。要创建多个不同长度的信号,可以使用 n_signals 和 length 标志,例如:
python generate_main.py --input_folder <模型文件夹名称> --n_signals 3 --length 60
要生成所有尺度的信号,使用 --generate_all_scales 标志。
创建音乐变体
要创建给定歌曲的变体,同时强制保持输入的总体结构(参见我们论文中的第 4.2 节),使用 --condition 标志:
python generate_main.py --input_folder <模型文件夹名称> --condition
带宽扩展
要使用训练好的模型执行带宽扩展,运行以下命令:
python extend.py --input_folder <模型文件夹名称> --lr_signal <低分辨率信号文件名>
lr_signal 是低分辨率音频的路径(即其采样率低于模型的采样率)。扩展后的输出将在所使用模型的 GeneratedSignals 文件夹中创建。为了计算扩展信号的 SNR 和 LSD,将低分辨率和真实高分辨率信号放在 inputs 文件夹中,文件名分别为:<文件名>_lr 和 <文件名>_hr。您可以选择提供用于创建低分辨率信号的抗混叠滤波器的频率响应。在 inputs 文件夹中放置一个包含两行的文本文件:频率响应的实部和虚部。滤波器的逆将用于反转低分辨率信号的瞬态区域,可以略微提高 SNR。
修复
修复是通过在重建信号中生成缺失部分,然后将其与输入拼接来完成的:
python inpaint.py --input_folder <模型文件夹名称>
您可以通过添加 --new 标志来创建不同的修复实现。
去噪
去噪后的信号就是重建的信号,所以在对噪声信号进行训练后,只需运行:
python generate_main.py --input_folder <模型文件夹名称> --reconstruct
运行示例
无条件生成
音乐:
python train_main.py --input_file TenorSaxophone_MedleyDB_185
语音:
python train_main.py --input_file trump_farewell_address_8 --speech
带宽扩展
首先,我们在VCTK语料库的几个连续句子上训练模型:
python train_main.py --input_file VCTK_p347_363_to_371 --speech
然后我们以同一说话人的新句子的低分辨率版本作为输入,并用训练好的模型进行扩展:
python extend.py --input_folder VCTK_p347_363_to_371 --lr_signal VCTK_p347_410_lr
要运行并校正低分辨率信号的瞬态,请执行:
python extend.py --input_folder VCTK_p347_363_to_371 --lr_signal VCTK_p347_410_lr --filter_file libDs4H
libDs4H是通过执行FFT(s_hr)/FFT(s_lr)得到的,其中s_lr是由librosa.resample创建的低分辨率信号。
修复
python train_main.py --input_file FMA_rock_for_inpainting --run_mode inpainting --inpainting_indices 89164 101164
降噪
python train_main.py --input_file JosephJoachim_BachAdagio_1904 --run_mode denoising --init_sample_rate 10000
这里我们将init_sample_rate设置为10KHz(默认为16KHz),因为旧录音的带宽有限。
预训练模型
除了自己运行示例外,您还可以下载预训练的生成器并直接进行推理。下载文件夹后,将它们放在outputs文件夹中并运行推理。
可以从Google Drive下载这些模型。
引用
如果您在研究中使用此代码,请引用我们的论文:
@article{greshler2021catch,
title={Catch-a-waveform: Learning to generate audio from a single short example},
author={Greshler, Gal and Shaham, Tamar and Michaeli, Tomer},
journal={Advances in Neural Information Processing Systems},
volume={34},
year={2021}
}
致谢
示例信号来自以下网站:
- 萨克斯管 - Medley-solos-DB。
- 语音 - VCTK语料库。
- 特朗普演讲 - 米勒中心,总统演讲数据库。
- 摇滚歌曲 - FMA数据库。
- 约瑟夫·约阿希姆的录音 - 约瑟夫·约阿希姆网站。
部分代码改编自:
- SinGAN。
- 重采样 - ResizeRight。
- MSS损失函数 - Jukexbox。
- 感谢Federico Miotello实现了多孔修复。











