

FaceChain
新闻
- 我们提供了新风格的训练脚本,为新风格LoRA提供自动训练以及相应的风格提示词,并在无限风格人像生成标签中提供一键调用功能!(2024年7月3日 UTC)
- 🚀🚀🚀 我们正在主分支上推出[FACT],提供10秒的惊人速度,并与标准的即用型LoRA和ControlNet无缝集成,同时改进了指令遵循能力!原始的基于训练的FaceChain已移至(https://github.com/modelscope/facechain/tree/v3.0.0)。(2024年5月28日 UTC)
- 我们的工作FaceChain-ImagineID和FaceChain-SuDe被CVPR 2024接收!(2024年2月27日 UTC)
介绍
如果您熟悉中文,可以阅读中文版本的README。
FaceChain是一个用于生成保持身份的人像的新型框架。在最新的FaceChain FACT(Face Adapter with deCoupled Training)版本中,只需1张照片和10秒钟,您就可以在不同设置下生成个人肖像(现在支持多种风格!)。FaceChain在肖像生成方面具有高度的可控性和真实性,包括基于文本到图像和修复的管道,并与ControlNet和LoRA无缝兼容。您可以通过FaceChain的Python脚本、熟悉的Gradio界面或sd webui生成肖像。 FaceChain由ModelScope提供支持。
ModelScope Studio 🤖 |API 🔥 | SD WebUI | HuggingFace Space 🤗


新闻
- 我们提供了新风格的训练脚本,为新风格LoRA提供自动训练以及相应的风格提示词,并在无限风格人像生成标签中提供一键调用功能!(2024年7月3日 UTC)
- 🚀🚀🚀 我们正在推出[FACT],提供10秒的惊人速度,并与标准的即用型LoRA和ControlNet无缝集成,同时改进了指令遵循能力!(2024年5月28日 UTC)
- 我们的工作FaceChain-ImagineID和FaceChain-SuDe被CVPR 2024接收!(2024年2月27日 UTC)
- 🏆🏆🏆阿里巴巴年度杰出开源项目,阿里巴巴年度开源先锋(杨柳,孙白贵)。(2024年1月20日 UTC)
- 我们与新加坡国立大学团队合作的工作InfoBatch被ICLR 2024接收(口头报告)!(2024年1月16日 UTC)
- 🏆OpenAtom 2023年度快速成长开源项目奖。(2023年12月20日 UTC)
- 添加SDXL管道🔥🔥🔥,图像细节明显改善。(2023年11月22日 UTC)
- 支持超分辨率🔥🔥🔥,提供多种分辨率选择(512512, 768768, 10241024, 20482048)。(2023年11月13日 UTC)
- 🏆FaceChain入选BenchCouncil Open100 (2022-2023)年度排名。(2023年11月8日 UTC)
- 添加虚拟试穿模块。(2023年10月27日 UTC)
- 添加玩霄版本在线免费应用。(2023年10月26日 UTC)
- 🏆1024程序员节AIGC应用工具最具商业价值奖。(2023年10月24日 UTC)
- 支持stable-diffusion-webui中的FaceChain🔥🔥🔥。(2023年10月13日 UTC)
- 单人和双人高性能修复,简化用户界面。(2023年9月9日 UTC)
- 更多技术细节可以在论文中查看。(2023年8月30日 UTC)
- 为Lora训练添加验证和集成,以及InpaintTab(目前在gradio中隐藏)。(2023年8月28日 UTC)
- 添加姿势控制模块。(2023年8月27日 UTC)
- 添加稳健的人脸lora训练模块,提高单张图片训练和风格-lora混合的性能。(2023年8月27日 UTC)
- HuggingFace Space现已可用!您可以直接使用🤗体验FaceChain。(2023年8月25日 UTC)
- 添加了精彩的提示词!参考:awesome-prompts-facechain(2023年8月18日 UTC)
- 以即插即用的方式支持一系列新的风格模型。(2023年8月16日 UTC)
- 支持自定义提示词。(2023年8月16日 UTC)
- Colab notebook现已可用!您可以直接使用
 体验FaceChain。(2023年8月15日 UTC)
体验FaceChain。(2023年8月15日 UTC)
待办事项
- 开发RLHF方法,使其质量更高。
- 支持更多美颜效果。
- 提供更多有趣的应用。
引用
如果FaceChain对您的研究有帮助,请在您的出版物中引用FaceChain
@article{liu2023facechain,
title={FaceChain: A Playground for Identity-Preserving Portrait Generation},
author={Liu, Yang and Yu, Cheng and Shang, Lei and Wu, Ziheng and
Wang, Xingjun and Zhao, Yuze and Zhu, Lin and Cheng, Chen and
Chen, Weitao and Xu, Chao and Xie, Haoyu and Yao, Yuan and
Zhou, Wenmeng and Chen Yingda and Xie, Xuansong and Sun, Baigui},
journal={arXiv preprint arXiv:2308.14256},
year={2023}
}
安装
兼容性验证
我们已在以下环境中验证了端到端执行:
- Python: py3.8, py3.10
- PyTorch: torch2.0.0, torch2.0.1
- CUDA: 11.7
- CUDNN: 8+
- 操作系统: Ubuntu 20.04, CentOS 7.9
- GPU: Nvidia-A10 24G
内存优化
建议安装Jemalloc以优化内存使用,从30G以上降至20G以下。以下是在ModelScope notebook中安装Jemalloc的示例。
apt-get install -y libjemalloc-dev
export LD_PRELOAD=/lib/x86_64-linux-gnu/libjemalloc.so
安装指南
支持以下安装方法:
1. ModelScope notebook【推荐】
ModelScope Notebook提供免费版本,允许ModelScope用户以最少的设置运行FaceChain应用,详见ModelScope Notebook
# 步骤1: 我的notebook -> PAI-DSW -> GPU环境
# 注意: 请使用: ubuntu20.04-py38-torch2.0.1-tf1.15.5-modelscope1.8.1
# 步骤2: 进入Notebook单元格,从github克隆FaceChain:
!GIT_LFS_SKIP_SMUDGE=1 git clone https://github.com/modelscope/facechain.git --depth 1
# 步骤3: 将工作目录更改为facechain,并安装依赖项:
import os
os.chdir('/mnt/workspace/facechain') # 您可以更改为自己的路径
print(os.getcwd())
!pip3 install gradio==3.47.1
!pip3 install controlnet_aux==0.0.6
!pip3 install python-slugify
!pip3 install diffusers==0.29.0
!pip3 install peft==0.11.1
# 步骤4: 启动应用服务,点击"public URL"或"local URL",上传您的图片
# 训练您自己的模型,然后生成您的数字分身。
!python3 app.py
或者,您也可以购买PAI-DSW实例(使用A10资源),选择ModelScope镜像,按照类似步骤运行FaceChain。
2. Docker
如果您熟悉使用docker,我们推荐使用这种方式:
# 步骤1: 在本地或云端准备带GPU的环境,我们推荐使用阿里云ECS,参考: https://www.aliyun.com/product/ecs
# 步骤2: 下载docker镜像(关于安装docker引擎,参考https://docs.docker.com/engine/install/)
# 中国大陆用户:
docker pull registry.cn-hangzhou.aliyuncs.com/modelscope-repo/modelscope:ubuntu20.04-cuda11.7.1-py38-torch2.0.1-tf1.15.5-1.8.1
# 中国大陆以外用户:
docker pull registry.us-west-1.aliyuncs.com/modelscope-repo/modelscope:ubuntu20.04-cuda11.7.1-py38-torch2.0.1-tf1.15.5-1.8.1
# 步骤3: 运行docker容器
docker run -it --name facechain -p 7860:7860 --gpus all registry.cn-hangzhou.aliyuncs.com/modelscope-repo/modelscope:ubuntu20.04-cuda11.7.1-py38-torch2.0.1-tf1.15.5-1.8.1 /bin/bash
# 注意: 您可能需要安装nvidia-container-runtime,按照以下说明操作:
# 1. 安装nvidia-container-runtime:https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html
# 2. sudo systemctl restart docker
# 步骤4: 在docker容器中安装gradio:
pip3 install gradio==3.47.1
pip3 install controlnet_aux==0.0.6
pip3 install python-slugify
pip3 install diffusers==0.29.0
pip3 install peft==0.11.1
# 步骤5 从github克隆facechain
GIT_LFS_SKIP_SMUDGE=1 git clone https://github.com/modelscope/facechain.git --depth 1
cd facechain
python3 app.py
# 注意: FaceChain目前假设单GPU环境,如果您的环境有多个GPU,请使用以下命令代替:
# CUDA_VISIBLE_DEVICES=0 python3 app.py
# 步骤6
运行应用服务器: 点击"public URL" --> 形式为: https://xxx.gradio.live
3. stable-diffusion-webui
-
选择
Extensions Tab,然后选择Install From URL(官方插件集成已完成,目前请从URL安装)。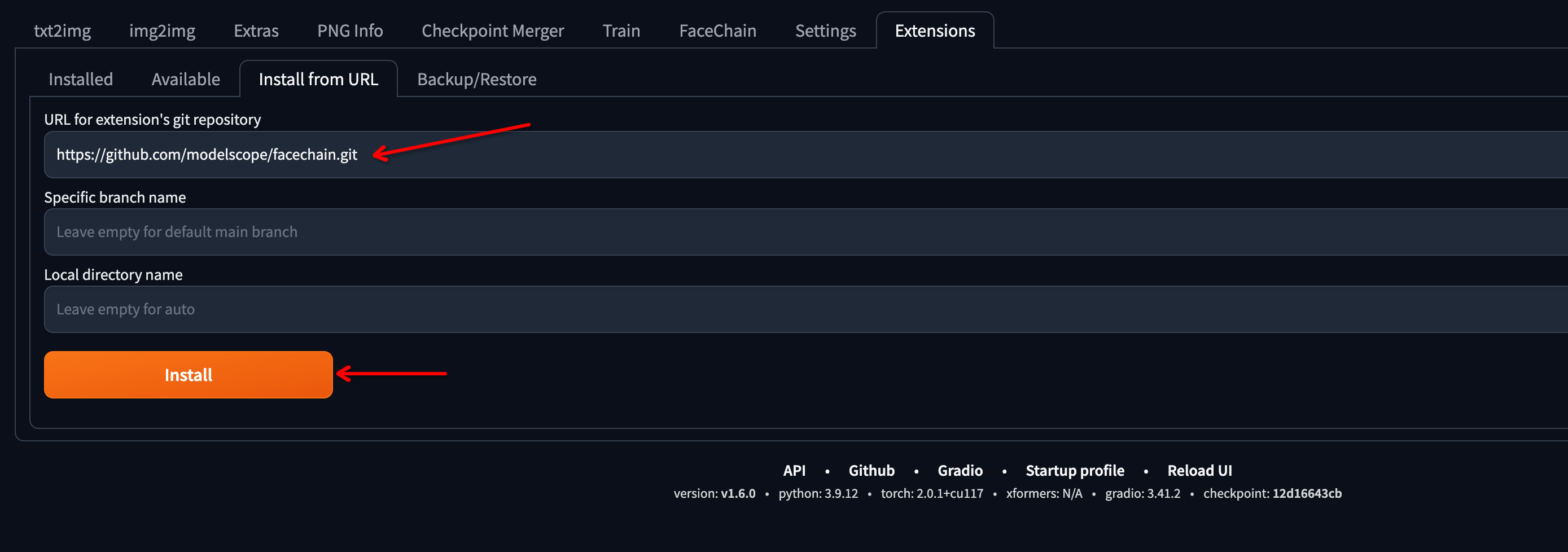
-
切换到
Installed,勾选FaceChain插件,然后点击Apply and restart UI。安装依赖项和下载模型可能需要一些时间。确保正确安装了"CUDA Toolkit",否则无法成功安装"mmcv"包。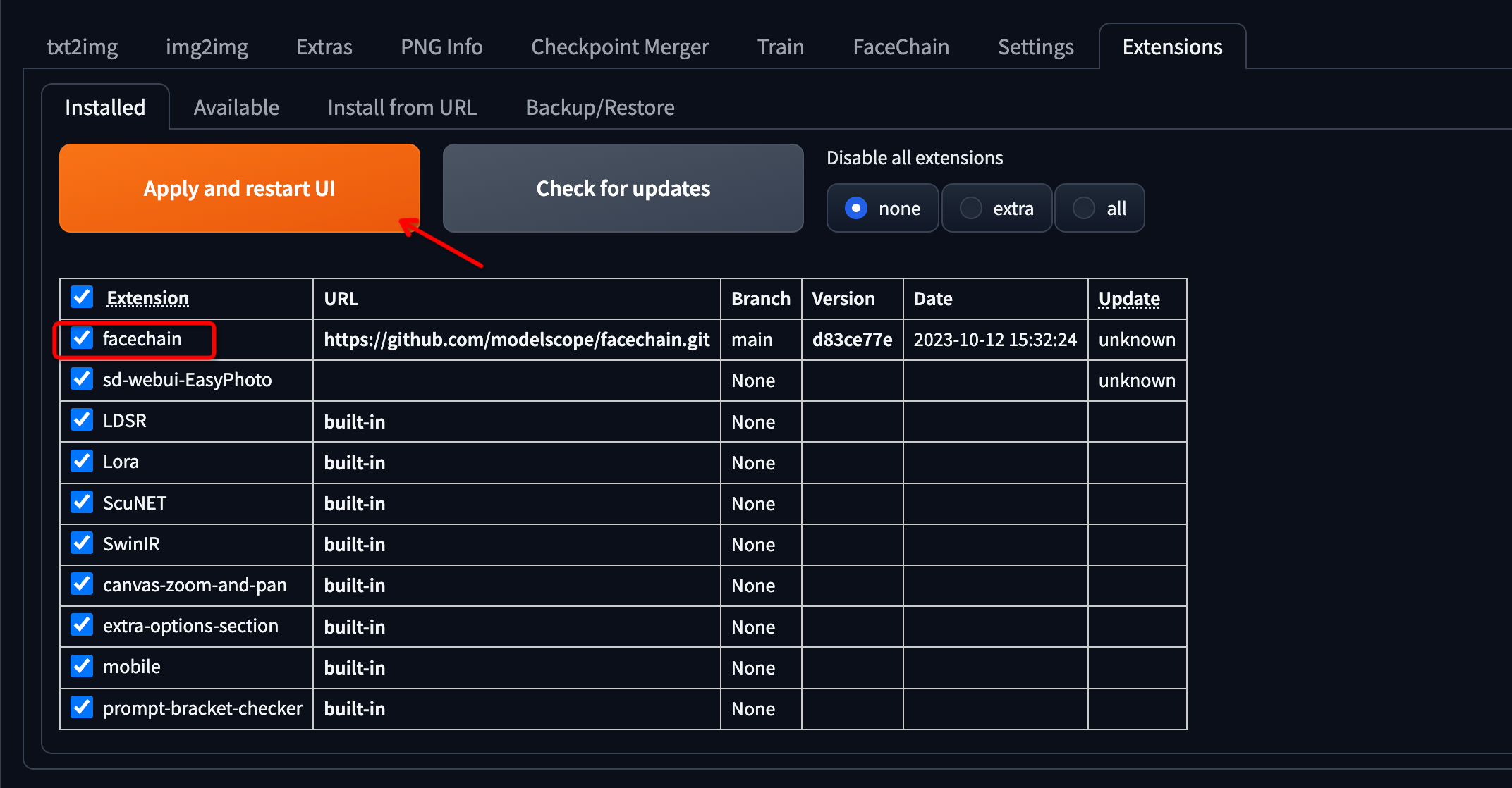
-
页面刷新后,出现
FaceChain标签表示安装成功。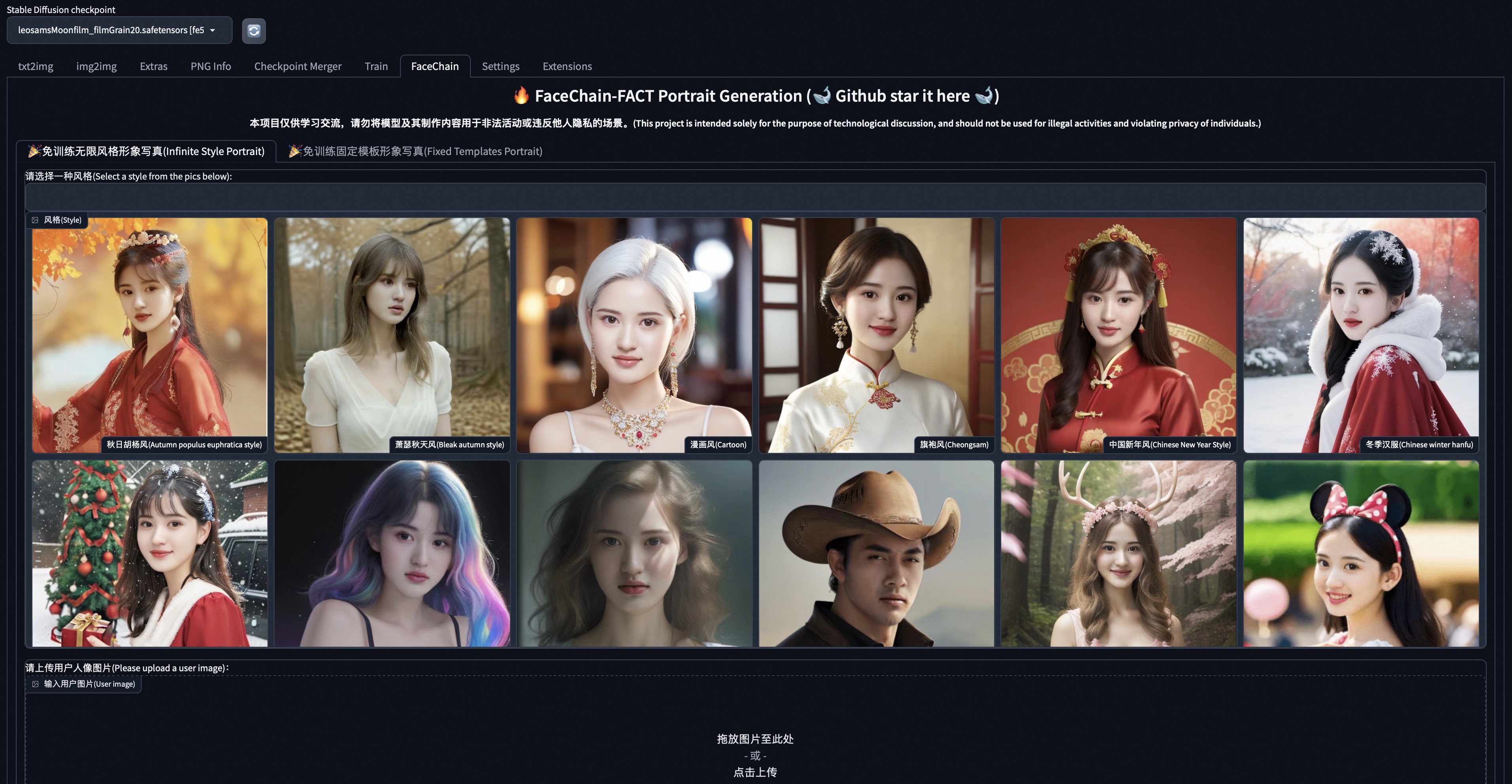
脚本执行
FaceChain支持在python环境中直接推理。进行无限风格人像生成推理时,请编辑run_inference.py中的代码:
# 使用姿态控制,默认为False
use_pose_model = False
# 包含用于人像生成的ID信息的输入图像路径
input_img_path = 'poses/man/pose2.png'
# 用于姿态控制的图像路径,仅在使用姿态控制时有效
pose_image = 'poses/man/pose1.png'
# 推理时生成的图像数量
num_generate = 5
# 风格模型的权重,详见styles
multiplier_style = 0.25
# 指定保存生成图像的文件夹,可根据需要修改此参数
output_dir = './generated'
# 选择的基础模型索引,详见facechain/constants.py
base_model_idx = 0
# 风格模型的索引,详见styles
style_idx = 0
然后执行:
python run_inference.py
您可以在output_dir中找到生成的个人数字图像照片。
进行固定模板人像生成推理时,请编辑run_inference_inpaint.py中的代码。
# 模板图像中的人脸数量
num_faces = 1
# 用于修复的人脸索引,从左到右计数
selected_face = 1
# 修复的强度,无需更改此参数
strength = 0.6
# 模板图像的路径
inpaint_img = 'poses/man/pose1.png'
# 包含用于人像生成的ID信息的输入图像路径
input_img_path = 'poses/man/pose2.png'
# 推理时生成的图像数量
num_generate = 1
# 指定保存生成图像的文件夹,可根据需要修改此参数
output_dir = './generated_inpaint'
然后执行:
python run_inference_inpaint.py
您可以在output_dir中找到生成的个人数字图像照片。
算法介绍
AI人像生成的能力来源于像Stable Diffusion这样的大型生成模型及其微调技术。由于大模型强大的泛化能力,可以通过在特定类型的数据和任务上进行微调来执行下游任务,同时保持模型整体的文本跟随和图像生成能力。基于训练和无需训练的AI人像生成的技术基础来自于对生成模型应用不同的微调任务。目前,大多数现有的AI人像工具采用"先训练后生成"的两阶段流程,其中微调任务是"生成固定角色ID的肖像照片",相应的训练数据是固定角色ID的多张图像。这种基于训练的流程的有效性取决于训练数据的规模,因此需要一定的图像数据支持和训练时间,这也增加了用户的成本。 与基于训练的流程不同,无训练流程将微调任务调整为"生成指定角色ID的肖像照片",即使用角色ID图像(脸部照片)作为额外输入,输出是保留输入ID的肖像照片。这种流程完全分离了离线训练和在线推理,允许用户仅基于一张照片,在10秒内直接使用微调模型生成肖像,避免了大量数据和训练时间的成本。无训练AI肖像生成的微调任务基于适配器模块。脸部照片通过固定权重的图像编码器和参数高效的特征投影层处理以获得对齐的特征,然后通过类似于文本条件的注意力机制输入到Stable Diffusion的U-Net模型中。此时,面部信息作为独立分支条件与文本信息一起输入模型进行推理,从而使生成的图像保持ID保真度。
基于人脸适配器的基本算法能够实现无训练AI肖像,但仍需进行一些调整以进一步提高其有效性。现有的无训练肖像工具通常存在以下问题:肖像图像质量差、肖像中文本跟随和风格保留能力不足、肖像面部可控性和丰富性差、与ControlNet和风格Lora等扩展的兼容性差。为解决这些问题,FaceChain将其归因于现有无训练AI肖像工具的微调任务耦合了过多角色ID以外的信息,并提出FaceChain人脸适配器解耦训练(FaceChain FACT)来解决这些问题。通过在数百万肖像数据上微调Stable Diffusion模型,FaceChain FACT可以实现指定角色ID的高质量肖像图像生成。FaceChain FACT的整体框架如下图所示。
FaceChain FACT的解耦训练包括两部分:将人脸从图像中解耦,以及将ID从人脸中解耦。现有方法通常将去噪肖像图像作为微调任务,这使得模型难以准确关注面部区域,从而影响基础Stable Diffusion模型的文本到图像能力。FaceChain FACT借鉴了换脸算法的顺序处理和区域控制优势,从结构和训练策略两个方面实现了将人脸从图像中解耦的微调方法。在结构上,与现有使用并行交叉注意力机制处理人脸和文本信息的方法不同,FaceChain FACT采用顺序处理方法,作为独立的适配器层插入原始Stable Diffusion的块中。这样,人脸适配在去噪过程中作为一个类似于换脸的独立步骤,避免了人脸和文本条件之间的干扰。在训练策略方面,除了原始的MSE损失函数外,FaceChain FACT还引入了面部适配增量正则化(FAIR)损失函数,控制适配器层中人脸适配步骤的特征增量,以关注面部区域。在推理过程中,用户可以通过修改人脸适配器的权重来灵活调整生成效果,平衡人脸的保真度和泛化能力,同时保持Stable Diffusion的文本到图像能力。FAIR损失函数的公式如下:
此外,为解决生成的面部可控性和丰富性差的问题,FaceChain FACT提出了一种将ID从人脸中解耦的训练方法,使得肖像过程只保留角色ID而不是整个面部。首先,为了更好地从人脸中提取ID信息,同时保留某些关键的面部细节,并更好地适应Stable Diffusion的结构,FaceChain FACT采用了基于Transformer架构的人脸特征提取器,该提取器在大规模人脸数据集上进行预训练。随后,将倒数第二层的所有token输入简单的注意力查询模型进行特征投影,从而确保提取的ID特征满足上述要求。此外,在训练过程中,FaceChain FACT使用无分类器引导(CFG)方法对同一ID的不同肖像图像进行随机洗牌和丢弃,从而确保用于去噪的输入人脸图像和目标图像可能具有相同ID的不同面孔,进一步防止模型过拟合于人脸的非ID信息。因此,FaceChain FACT与FaceChain的大量精致风格具有高度兼容性,如下所示。
FaceChain使用的模型列表:
[1] 人脸识别模型TransFace [2] 人脸检测模型DamoFD [3] 人体解析模型M2FP [4] 皮肤修复模型ABPN [5] 人脸融合模型 [6] FaceChain FACT模型 [7] 人脸属性识别模型FairFace
更多信息:
- ModelScope库
ModelScope库为构建ModelScope的模型生态系统提供了基础,包括将各种模型集成到ModelScope中的接口和实现。
- 向ModelScope贡献模型
许可证
本项目采用Apache许可证(版本2.0)。











