
 访问官网
访问官网 Github
Github 文档
文档 论文
论文SHARK
高性能机器学习发行版
我们目前正在重建SHARK,以利用Turbine。在此完成之前,请确保您使用.exe版本或SHARK-1.0分支的代码,以获得正常工作的SHARK。

![]()
先决条件 - 驱动程序
安装您的Windows硬件驱动程序
- [AMD RDNA用户] 在这里下载最新驱动程序(支持的最旧版本为23.2.1)。
- [macOS用户] 在这里下载并安装1.3.216版本的Vulkan SDK。较新的SDK版本将无法正常工作。
- [Nvidia用户] 在这里下载并安装最新的CUDA / Vulkan驱动程序。
Linux驱动程序
- MESA / RADV驱动程序不支持FP16。请使用最新的AMGPU-PRO驱动程序(非专业版的开源驱动程序也无法正常工作)或最新的NVidia Linux驱动程序。
其他用户请确保您已从这里获取了最新的供应商驱动程序和Vulkan SDK,如果您正在使用Vulkan,请确保在终端窗口中运行vulkaninfo。
Windows 10/11用户的SHARK Stable Diffusion快速入门
从上面的(先决条件)[https://github.com/nod-ai/SHARK#install-your-hardware-drivers]链接安装驱动程序。
下载稳定版本或最新的SHARK 1.0预发布版本。
双击.exe文件,或从命令行运行(推荐),您应该可以在浏览器中访问UI。
如果您有自定义模型,请将它们放在.exe所在目录下的models/文件夹中。
享受吧。
更多安装说明
* 我们建议您每次下载新EXE版本时都将其下载到新文件夹中。如果您将其下载到与先前安装相同的文件夹中,您必须删除旧的`*.vmfb`文件,命令为`rm *.vmfb`。您也可以使用`--clear_all`标志一次性清除所有旧文件。 * 如果您最近更新了驱动程序或此二进制文件(EXE文件),建议您使用`--clear_all`清除所有本地缓存。运行
- 打开命令提示符或Powershell终端,切换目录(
cd)到.exe文件所在的文件夹。然后从命令提示符运行EXE。这样,如果发生错误,您可以复制并粘贴它来寻求帮助。(如果它始终无错误地运行,您也可以直接双击EXE) - 第一次运行可能需要几分钟时间,因为模型需要下载并编译。感谢您的耐心等待。下载大约为5GB。
- 您可能会看到Windows Defender消息,要求您授予打开Web服务器端口的权限。请接受。
- 打开浏览器访问Stable Diffusion Web服务器。默认情况下,端口是8080,因此您可以访问http://localhost:8080/。
- 如果您更喜欢始终在浏览器中运行,请在运行EXE时使用
--ui=web命令参数。
停止
- 选择正在运行EXE的命令提示符。按CTRL-C并等待片刻或关闭终端。
高级安装(仅限开发人员)
开发人员的高级安装(Windows、Linux和macOS)
Windows 10/11用户
- 如果您尚未安装,请从这里安装Git for Windows。
检出代码
git clone https://github.com/nod-ai/SHARK.git
cd SHARK
切换到正确的分支(重要!)
目前,SHARK正在main分支上为Turbine进行重建。当前强烈建议您不要使用main分支,除非您正在参与重建工作,否则不应期望该分支上的代码能生成用于图像生成的可工作应用程序。因此,目前您需要切换到SHARK-1.0分支并使用稳定代码。
git checkout SHARK-1.0
以下设置说明假设您在此分支上。
设置Python虚拟环境及依赖项
Windows 10/11用户
- 从这里安装最新的Python 3.11.x版本。
允许安装脚本在Powershell中运行
set-executionpolicy remotesigned
设置venv并安装必要的包(torch-mlir, nodLabs/Shark, ...)
./setup_venv.ps1 #您可以重新运行此脚本以获取最新版本
Linux / macOS用户
./setup_venv.sh
source shark1.venv/bin/activate
在您的设备上运行Stable Diffusion - WebUI
Windows 10/11用户
(shark1.venv) PS C:\g\shark> cd .\apps\stable_diffusion\web\
(shark1.venv) PS C:\g\shark\apps\stable_diffusion\web> python .\index.py
Linux / macOS用户
(shark1.venv) > cd apps/stable_diffusion/web
(shark1.venv) > python index.py
访问 http://localhost:8080/?__theme=dark 上的Stable Diffusion
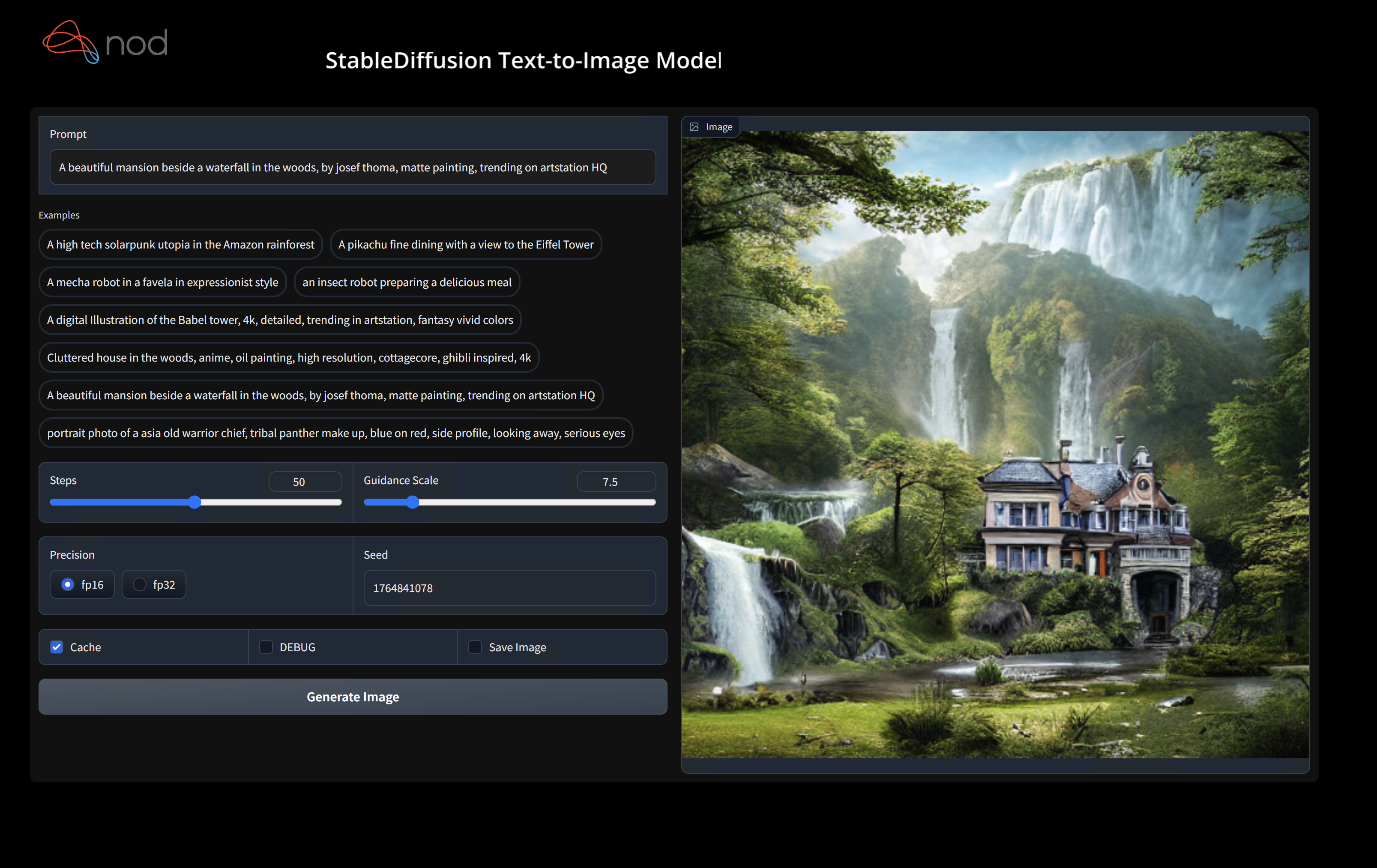
在您的设备上运行Stable Diffusion - 命令行
Windows 10/11用户
(shark1.venv) PS C:\g\shark> python .\apps\stable_diffusion\scripts\main.py --app="txt2img" --precision="fp16" --prompt="tajmahal, snow, sunflowers, oil on canvas" --device="vulkan"
Linux / macOS用户
python3.11 apps/stable_diffusion/scripts/main.py --app=txt2img --precision=fp16 --device=vulkan --prompt="tajmahal, oil on canvas, sunflowers, 4k, uhd"
您可以将vulkan替换为cpu以在CPU上运行,或替换为cuda以在CUDA设备上运行。如果您有多个vulkan设备,可以使用--device=vulkan://1等来指定设备。
在AMD 7900XTX上的输出可能如下所示:
每步平均时间:47.19188690185547毫秒/次
Clip推理时间(毫秒):109.531
VAE推理时间(毫秒):78.590
图像生成总时间:2.5788655281066895秒
以下是生成的一些示例:


如果您在运行它时遇到任何问题,请在SHARK Discord服务器上找到我们。
二进制安装
设置新的pip虚拟环境
此步骤为Python设置一个新的VirtualEnv
python --version #检查您是否在Linux、macOS或Windows Powershell上
要生成单个调度的基准测试,可以在pytest命令行参数中添加`--dispatch_benchmarks=All --dispatch_benchmarks_dir=<output_dir>`。
如果您只想编译特定的调度,可以用空格分隔的字符串指定它们,而不是使用`"All"`。例如:`--dispatch_benchmarks="0 1 2 10"`。
例如,要为CUDA上的MiniLM生成和运行调度基准测试:
pytest -k "MiniLM and torch and static and cuda" --benchmark_dispatches=All -s --dispatch_benchmarks_dir=./my_dispatch_benchmarks
给定的命令将会在`<dispatch_benchmarks_dir>/<model_name>/`下生成一个`ordered_dispatches.txt`文件,列出并排序调度及其延迟时间,并为每个调度生成包含.mlir、.vmfb以及该调度基准测试结果的文件夹。
如果您想将其合并到Python脚本中,可以在初始化`SharkInference`时传递`dispatch_benchmarks`和`dispatch_benchmarks_dir`命令,基准测试将在编译时生成。例如:
shark_module = SharkInference( mlir_model, device=args.device, mlir_dialect="tm_tensor", dispatch_benchmarks="all", dispatch_benchmarks_dir="results" )
输出将包括:
- 一个名为`ordered-dispatches.txt`的有序列表,列出所有调度及其运行时间。
- 在指定的目录中,将为每个调度创建一个目录(所有调度都会生成mlir文件,但仅为指定的调度生成已编译的二进制文件和基准测试数据)。
- 一个包含调度基准测试的.mlir文件。
- 一个包含调度基准测试的已编译.vmfb文件。
- 一个仅包含hal可执行文件的.mlir文件。
- 一个hal可执行文件的已编译.vmfb文件。
- 一个包含基准测试输出的.txt文件。
有关如何从SHARK tank运行模型测试和基准测试的更多说明,请参阅tank/README.md。
</details>
<details>
<summary>API 参考</summary>
### Shark Inference API
from shark.shark_importer import SharkImporter
SharkImporter从torch、tensorflow或tf-lite模块导入mlir文件。
mlir_importer = SharkImporter( torch_module, (input), frontend="torch", #tf, #tf-lite ) torch_mlir, func_name = mlir_importer.import_mlir(tracing_required=True)
SharkInference接收linalg、mhlo和tosa方言的mlir。
from shark.shark_inference import SharkInference shark_module = SharkInference(torch_mlir, device="cpu", mlir_dialect="linalg") shark_module.compile() result = shark_module.forward((input))
### 运行MHLO IR的示例。
from shark.shark_inference import SharkInference import numpy as np
mhlo_ir = r"""builtin.module { func.func @forward(%arg0: tensor<1x4xf32>, %arg1: tensor<4x1xf32>) -> tensor<4x4xf32> { %0 = chlo.broadcast_add %arg0, %arg1 : (tensor<1x4xf32>, tensor<4x1xf32>) -> tensor<4x4xf32> %1 = "mhlo.abs"(%0) : (tensor<4x4xf32>) -> tensor<4x4xf32> return %1 : tensor<4x4xf32> } }"""
arg0 = np.ones((1, 4)).astype(np.float32) arg1 = np.ones((4, 1)).astype(np.float32) shark_module = SharkInference(mhlo_ir, device="cpu", mlir_dialect="mhlo") shark_module.compile() result = shark_module.forward((arg0, arg1))
</details>
## 使用REST API的示例
* [设置SHARK以在Blender中使用](./docs/shark_sd_blender.md)
* [设置SHARK以在Koboldcpp中使用](./docs/shark_sd_koboldcpp.md)
## 支持和验证的模型
SHARK持续支持最新的机器学习模型创新:
| TF HuggingFace模型 | SHARK-CPU | SHARK-CUDA | SHARK-METAL |
|---------------------|----------|----------|-------------|
| BERT | :green_heart: | :green_heart: | :green_heart: |
| DistilBERT | :green_heart: | :green_heart: | :green_heart: |
| GPT2 | :green_heart: | :green_heart: | :green_heart: |
| BLOOM | :green_heart: | :green_heart: | :green_heart: |
| Stable Diffusion | :green_heart: | :green_heart: | :green_heart: |
| Vision Transformer | :green_heart: | :green_heart: | :green_heart: |
| ResNet50 | :green_heart: | :green_heart: | :green_heart: |
有关SHARK支持的完整模型列表,请参阅[tank/README.md](https://github.com/nod-ai/SHARK/blob/main/tank/README.md)。
## 沟通渠道
* [SHARK Discord服务器](https://discord.gg/RUqY2h2s9u):与SHARK团队和其他用户进行实时讨论
* [GitHub问题](https://github.com/nod-ai/SHARK/issues):功能请求、bug等
## 相关项目
<details>
<summary>IREE项目渠道</summary>
* [上游IREE问题](https://github.com/google/iree/issues):功能请求、bug和其他工作跟踪
* [上游IREE Discord服务器](https://discord.gg/wEWh6Z9nMU):与核心团队和合作者进行日常开发讨论
* [iree-discuss邮件列表](https://groups.google.com/forum/#!forum/iree-discuss):公告、一般和低优先级讨论
</details>
<details>
<summary>MLIR和Torch-MLIR项目渠道</summary>
* LLVM [Discord](https://discord.gg/xS7Z362)上的`#torch-mlir`频道 - 这是最活跃的沟通渠道
* Torch-MLIR GitHub问题[在此](https://github.com/llvm/torch-mlir/issues)
* LLVM Discourse的[`torch-mlir`部分](https://llvm.discourse.group/c/projects-that-want-to-become-official-llvm-projects/torch-mlir/41)
* 每周一上午9点PST的例会。有关更多信息,请参阅[此处](https://discourse.llvm.org/t/community-meeting-developer-hour-refactoring-recurring-meetings/62575)。
* LLVM Discourse中的[MLIR话题](https://llvm.discourse.group/c/llvm-project/mlir/31)。SHARK和IREE由[MLIR](https://mlir.llvm.org)支持并严重依赖其功能。
</details>
## 许可协议
nod.ai SHARK根据Apache 2.0许可协议和LLVM例外条款进行许可。有关更多信息,请参阅[LICENSE](LICENSE)。











