访问官网
访问官网 Github
Github 论文
论文加速扫描


该包在 GPU 上实现了最快的一阶并行关联扫描,用于前向和后向计算。
该扫描高效地解决了形如 x[t] = gate[t] * x[t-1] + token[t] 的一阶递归问题,这在状态空间模型和线性 RNN 中很常见。
accelerated_scan.warp C++ CUDA 内核使用分块处理算法,利用了每个层级上可用的最快 GPU 通信原语:在 32 线程的 warp 内使用warp 洗牌,在线程块内的 warp 之间使用共享内存(SRAM)。每个通道维度的一个序列被限制在一个线程块内。
分块扫描的推导被用来将树级 Blelloch 算法扩展到块级。
accelerated_scan.triton 中提供了类似的实现,使用 Triton 的 tl.associative_scan 原语。它需要 Triton 2.2 版本以使用其 enable_fp_fusion 标志。
快速开始:
pip install accelerated-scan
import torch
from accelerated_scan.warp import scan # 纯 C++ 内核,比 cub 更快
#from accelerated_scan.triton import scan # 使用 tl.associative_scan
#from accelerated_scan.ref import scan # 参考 torch 实现
# 序列长度必须是 32 到 65536 之间的 2 的幂
# 如果你需要不同的长度,请联系我!
batch_size, dim, seqlen = 3, 1536, 4096
gates = 0.999 + 0.001 * torch.rand(batch_size, dim, seqlen, device="cuda")
tokens = torch.rand(batch_size, dim, seqlen, device="cuda")
out = scan(gates, tokens)
为确保数值等效性,在 Torch 中提供了树的参考实现。可以使用 torch.compile 加速。
基准测试:
在 nanokitchen 中查看更多基准测试:https://github.com/proger/nanokitchen
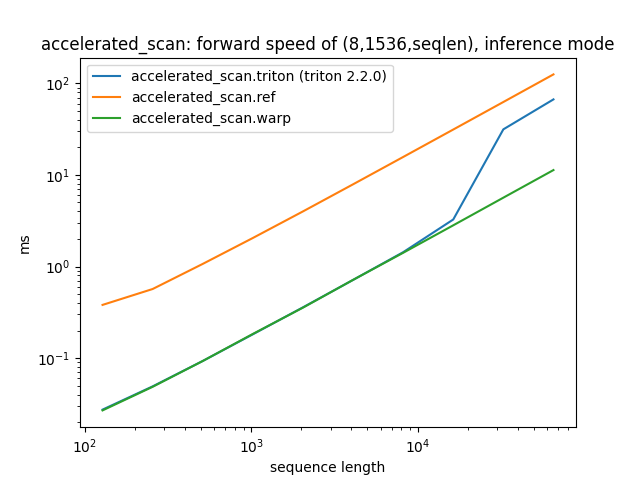
(8,1536,seqlen) 的前向速度,推理模式:
序列长度 accelerated_scan.triton (triton 2.2.0) accelerated_scan.ref accelerated_scan.warp
0 128.0 0.027382 0.380874 0.026844
1 256.0 0.049104 0.567916 0.048593
2 512.0 0.093008 1.067906 0.092923
3 1024.0 0.181856 2.048471 0.183581
4 2048.0 0.358250 3.995369 0.355414
5 4096.0 0.713511 7.897022 0.714536
6 8192.0 1.433052 15.698944 1.411390
7 16384.0 3.260965 31.305046 2.817152
8 32768.0 31.459671 62.557182 5.645697
9 65536.0 66.787331 125.208572 11.297921
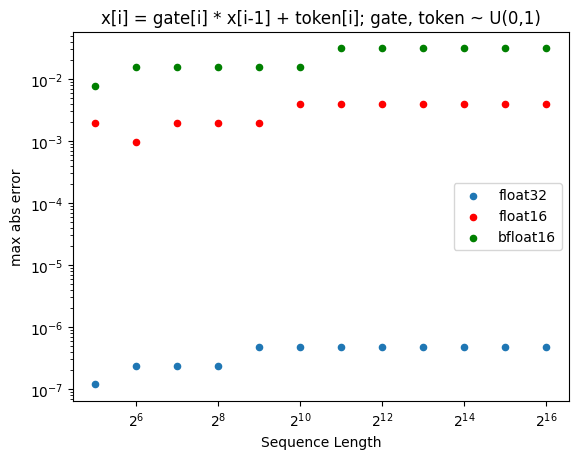
精度说明
当门控和标记从 0..1 均匀采样时,bfloat16 精度的缺乏主导了误差(与参考实现相比):