
 Github
Github 论文
论文sequitur
sequitur是一个库,允许您仅用两行代码创建和训练序列数据的自动编码器。它在PyTorch中实现了三种不同的自动编码器架构和预定义的训练循环。sequitur非常适合处理从单变量和多变量时间序列到视频的各种序列数据,专为那些想要快速开始使用自动编码器的人设计。
import torch
from sequitur.models import LINEAR_AE
from sequitur import quick_train
train_seqs = [torch.randn(4) for _ in range(100)] # 100个长度为4的序列
encoder, decoder, _, _ = quick_train(LINEAR_AE, train_seqs, encoding_dim=2, denoise=True)
encoder(torch.randn(4)) # => torch.tensor([0.19, 0.84])
每个自动编码器学习将输入序列表示为低维的、固定大小的向量。这对于查找序列之间的模式、对序列进行聚类或将序列转换为其他算法的输入很有用。
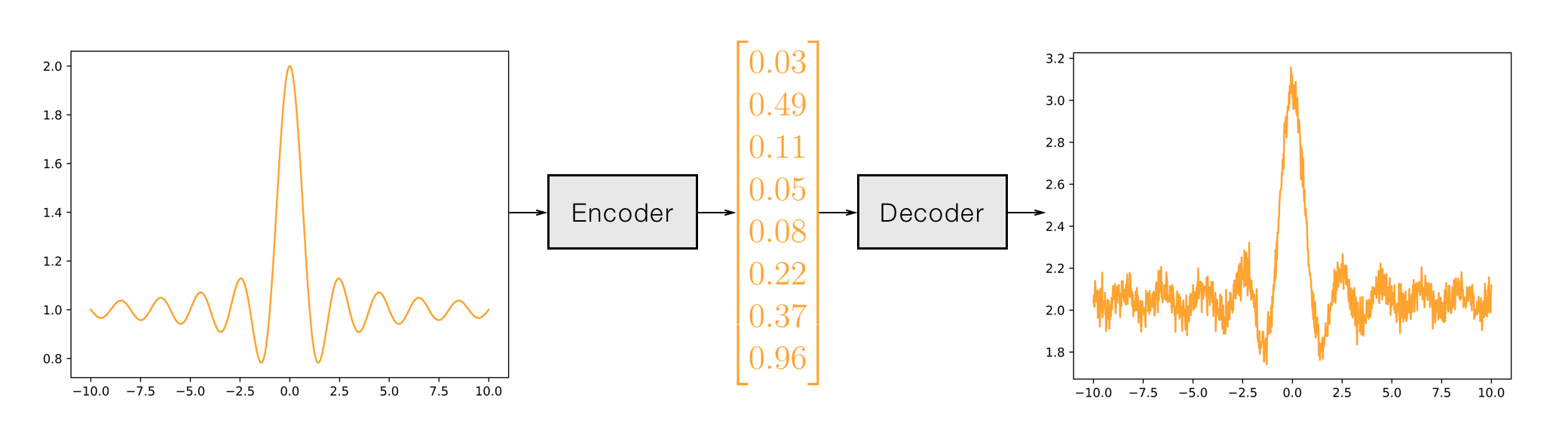
引用
AgriSen-COG,一个多国家、多时间的大规模Sentinel-2基准数据集,用于使用深度学习进行作物映射
安装
需要Python 3.X和PyTorch 1.2.X
您可以使用pip安装sequitur:
$ pip install sequitur
入门
1. 准备数据
首先,您需要准备一组示例序列来训练自动编码器。这个训练集应该是一个torch.Tensor对象的列表,其中每个张量的形状为[num_elements, *num_features]。因此,如果您训练集中的每个示例是一个由10个5x5矩阵组成的序列,那么每个示例将是一个形状为[10, 5, 5]的张量。
2. 选择自动编码器
接下来,您需要选择一个自动编码器模型。如果您处理的是数字序列(例如时间序列)或1D向量(例如词向量),那么应该使用LINEAR_AE或LSTM_AE模型。对于2D矩阵序列(例如视频)或3D矩阵(例如fMRI扫描),您应该使用CONV_LSTM_AE。每个模型都是一个PyTorch模块,可以像这样导入:
from sequitur.models import CONV_LSTM_AE
关于每个模型的更多细节在下面的"模型"部分。
3. 训练自动编码器
从这里开始,您可以自己初始化模型并编写自己的训练循环,或者导入quick_train函数并插入模型、训练集和所需的编码大小,如下所示:
import torch
from sequitur.models import CONV_LSTM_AE
from sequitur import quick_train
train_set = [torch.randn(10, 5, 5) for _ in range(100)]
encoder, decoder, _, _ = quick_train(CONV_LSTM_AE, train_set, encoding_dim=4)
训练后,quick_train返回encoder和decoder模型,它们是可以编码和解码新序列的PyTorch模块。可以这样使用它们:
x = torch.randn(10, 5, 5)
z = encoder(x) # 形状为[4]的张量
x_prime = decoder(z) # 形状为[10, 5, 5]的张量
API
训练您的模型
quick_train(model, train_set, encoding_dim, verbose=False, lr=1e-3, epochs=50, denoise=False, **kwargs)
让您只用一行代码就能训练自动编码器。如果您不想创建自己的训练循环,这很有用。训练涉及学习每个输入序列的向量编码,从编码重构原始序列,并计算重构输入与原始输入之间的损失(均方误差)。使用Adam优化器更新自动编码器的权重。
参数:
model(torch.nn.Module):要训练的自动编码器模型(从sequitur.models导入)train_set(list):用于训练模型的序列列表(每个序列是一个torch.Tensor);形状为[num_examples, seq_len, *num_features]encoding_dim(int):所需的向量编码大小verbose(bool, 可选 (默认=False)):是否在每个epoch打印损失lr(float, 可选 (默认=1e-3)):学习率epochs(int, 可选 (默认=50)):训练的epoch数**kwargs:实例化model时要传入的参数
返回:
encoder(torch.nn.Module):训练好的编码器模型;接受一个序列(作为张量)作为输入,返回序列的编码,形状为[encoding_dim]的张量decoder(torch.nn.Module):训练好的解码器模型;接受一个编码(作为张量)并返回解码后的序列encodings(list):对应于训练集中每个序列的最终向量编码的张量列表losses(list):每个epoch的平均MSE值列表
模型
每个自动编码器都继承自torch.nn.Module,并有一个encoder属性和一个decoder属性,它们也都继承自torch.nn.Module。
数字序列
LINEAR_AE(input_dim, encoding_dim, h_dims=[], h_activ=torch.nn.Sigmoid(), out_activ=torch.nn.Tanh())
由堆叠在一起的全连接层组成。只能用于处理数字序列,不适用于向量或矩阵。
参数:
input_dim(int):每个输入序列的大小encoding_dim(int):向量编码的大小h_dims(list, 可选 (默认=[])):编码器的隐藏层大小列表h_activ(torch.nn.Module 或 None, 可选 (默认=torch.nn.Sigmoid())):用于隐藏层的激活函数;如果为None,则不使用激活函数out_activ(torch.nn.Module 或 None, 可选 (默认=torch.nn.Tanh())):用于编码器输出层的激活函数;如果为None,则不使用激活函数
示例:
要创建上图所示的自动编码器,使用以下参数:
from sequitur.models import LINEAR_AE
model = LINEAR_AE(
input_dim=10,
encoding_dim=4,
h_dims=[8, 6],
h_activ=None,
out_activ=None
)
x = torch.randn(10) # 10个数字的序列 z = model.encoder(x) # z的形状为 [4] x_prime = model.decoder(z) # x_prime的形状为 [10]
#### 一维向量序列
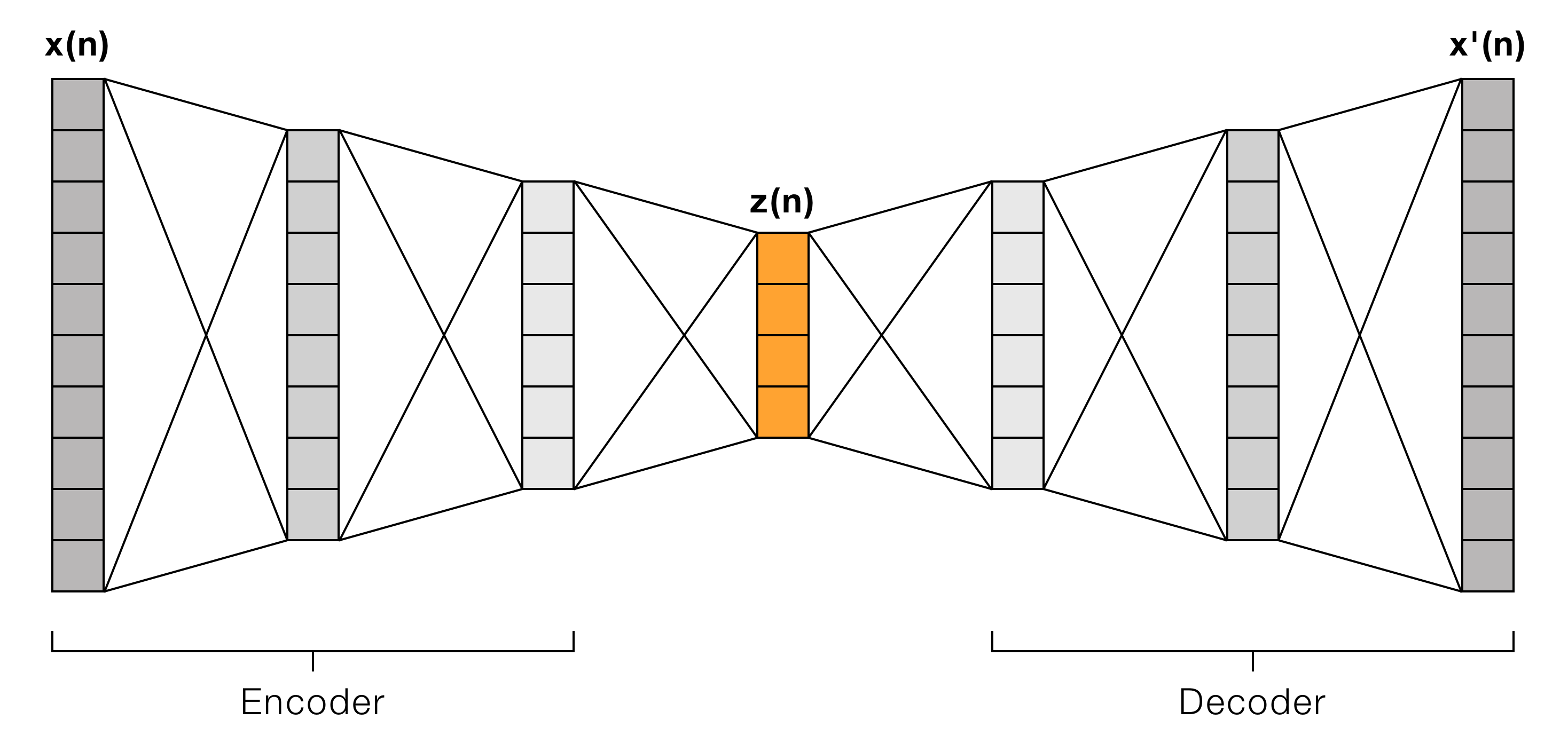
**`LSTM_AE(input_dim, encoding_dim, h_dims=[], h_activ=torch.nn.Sigmoid(), out_activ=torch.nn.Tanh())`**
用于向量序列的自编码器,由堆叠的LSTM组成。可以在不同长度的序列上进行训练。
<img src="https://yellow-cdn.veclightyear.com/0a4dffa0/009da057-6e0d-428e-8ecd-29cd7e6a4b59.png" />
**参数:**
- `input_dim` _(int)_:每个序列元素(向量)的大小
- `encoding_dim` _(int)_:编码向量的大小
- `h_dims` _(列表,可选 (默认=[]))_:编码器隐藏层大小的列表
- `h_activ` _(torch.nn.Module 或 None,可选 (默认=torch.nn.Sigmoid()))_:用于隐藏层的激活函数;如果为`None`,则不使用激活函数
- `out_activ` _(torch.nn.Module 或 None,可选 (默认=torch.nn.Tanh()))_:用于编码器输出层的激活函数;如果为`None`,则不使用激活函数
**示例:**
要创建上图所示的自编码器,请使用以下参数:
```python
from sequitur.models import LSTM_AE
model = LSTM_AE(
input_dim=3,
encoding_dim=7,
h_dims=[64],
h_activ=None,
out_activ=None
)
x = torch.randn(10, 3) # 10个3维向量的序列
z = model.encoder(x) # z的形状为 [7]
x_prime = model.decoder(z, seq_len=10) # x_prime的形状为 [10, 3]
二维/三维矩阵序列
CONV_LSTM_AE(input_dims, encoding_dim, kernel, stride=1, h_conv_channels=[1], h_lstm_channels=[])
用于二维或三维矩阵/图像序列的自编码器,大致基于《Beyond Short Snippets: Deep Networks for Video Classification》中描述的CNN-LSTM架构。使用CNN为输入序列中的每个图像创建向量编码,然后使用LSTM为向量序列创建编码。
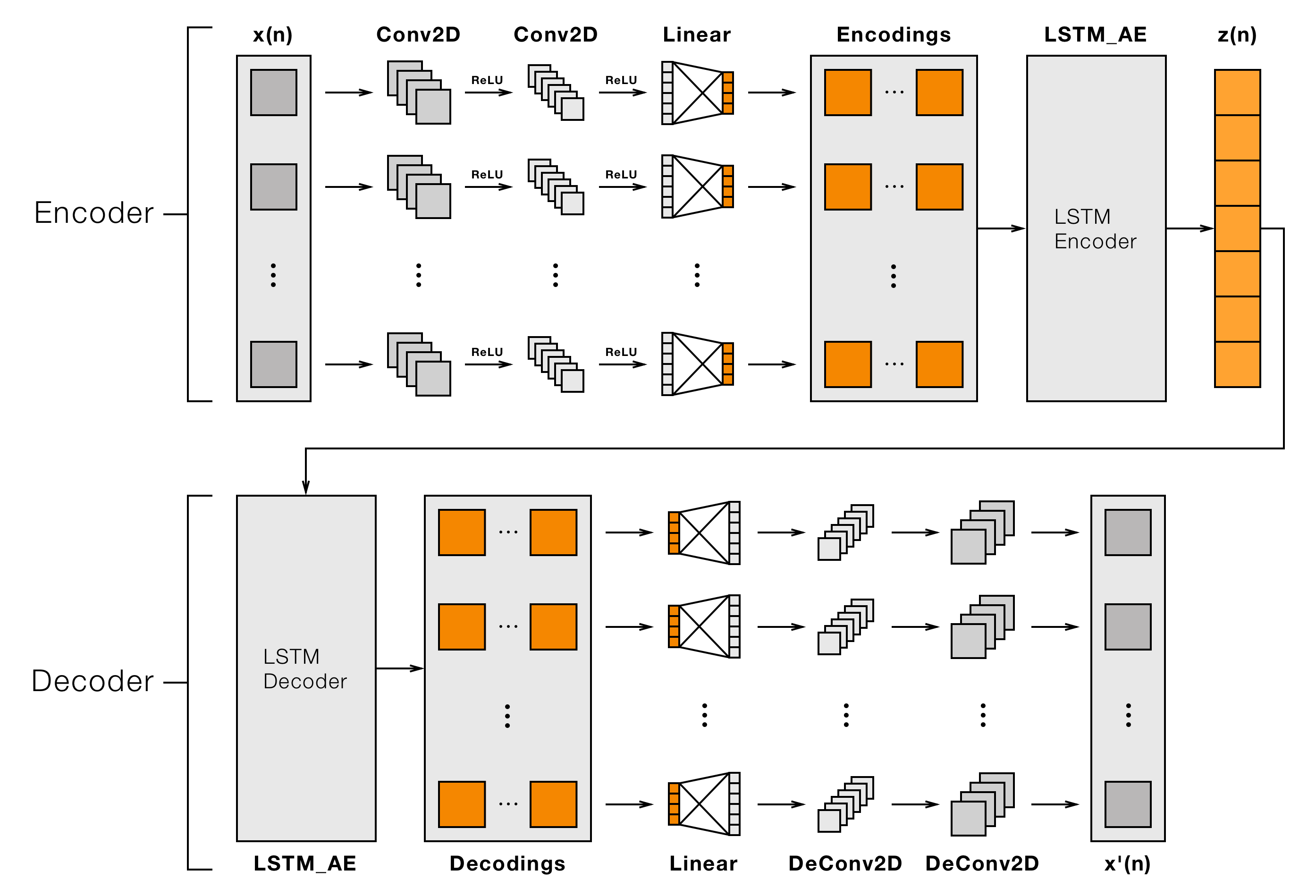
参数:
input_dims(元组):输入序列中每个二维或三维图像的形状encoding_dim(int):编码向量的大小kernel(int 或 元组):卷积核的大小;使用元组可为每个维度指定不同的大小stride(int 或 元组,可选 (默认=1)):卷积的步幅;使用元组可为每个维度指定不同的步幅h_conv_channels(列表,可选 (默认=[1])):卷积层隐藏通道大小的列表h_lstm_channels(列表,可选 (默认=[])):LSTM层隐藏通道大小的列表
示例:
from sequitur.models import CONV_LSTM_AE
model = CONV_LSTM_AE(
input_dims=(50, 100),
encoding_dim=16,
kernel=(5, 8),
stride=(3, 5),
h_conv_channels=[4, 8],
h_lstm_channels=[32, 64]
)
x = torch.randn(22, 50, 100) # 22个50x100图像的序列
z = model.encoder(x) # z的形状为 [16]
x_prime = model.decoder(z, seq_len=22) # x_prime的形状为 [22, 50, 100]











