
 Github
Github Huggingface
Huggingface 论文
论文SECap: 使用大型语言模型进行语音情感描述
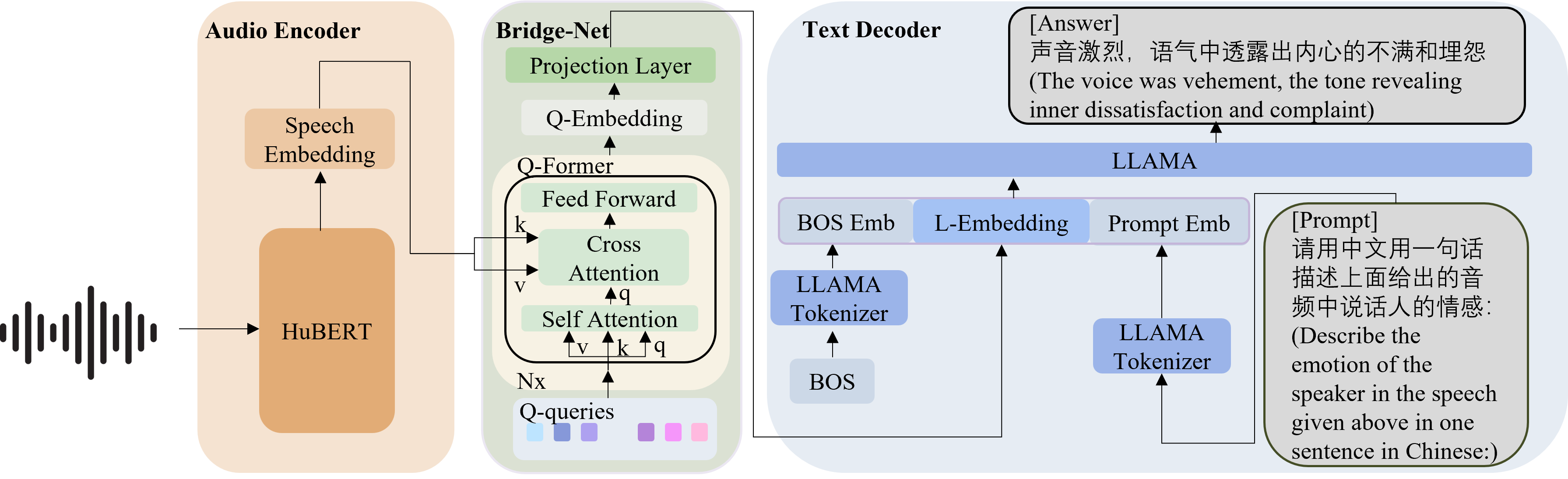
本仓库包含论文"SECap: 使用大型语言模型进行语音情感描述"的实现。更多详细信息请参阅我们的论文。
该仓库包括模型代码、训练和测试脚本,以及测试数据集。测试数据集由600个wav音频文件及其相应的情感描述组成。
数据集
我们在dataset文件夹中公开了600个测试数据集。该数据集包含600个wav音频文件及其相应的情感描述。
dataset文件夹包含以下文件:
wav:包含600个wav音频文件的文件夹。
text.txt:包含600个音频文件转录文本的文件。
fid2captions.json:包含600个音频文件情感描述的文件。
下载
您可以使用以下命令简单地下载仓库:
git clone https://github.com/thuhcsi/SECap.git
安装
要安装项目依赖项,请使用以下命令:
conda env create -f environment.yml
预训练模型
您需要下载两个文件来运行代码。第一个是model.ckpt,这是SECaps的预训练模型。第二个是weights,这是依赖项所需的权重。
如果您下载了weights.tar.gz,您需要解压它并将文件放在weights文件夹中。
tar -xvf weights.tar.gz -C path/to/SECap
然后您需要将model.ckpt文件和weights文件夹放在主文件夹(SECap)中。
您可以从夸克网盘或谷歌云盘下载model.ckpt并将其放在主文件夹中。
您可以从夸克网盘下载weights或从谷歌云盘下载weights.tar.gz并将其放在主文件夹中。
同时,我们在huggingface模型库中提供了预训练的检查点。您也可以从这里下载model.ckpt和weights.tar.gz。
推理和测试
如果您想在自己的数据上测试模型,请使用inference.py脚本。例如:
cd scripts
python inference.py --wavdir /path/to/your/audio.wav
如果您想在提供的600个音频文件及其情感描述的测试数据集上测试模型,请使用test.py脚本。例如:
cd scripts
python test.py
训练
如果您想训练模型,请使用train.py脚本。但首先,您需要创建一个训练数据集。训练数据集应该是一个包含音频文件及其相应情感描述的文件夹。
例如:
cd scripts
python train.py
计算相似度
我们使用句子相似度来评估生成的描述。
具体来说,我们对600个音频文件生成8次描述,计算每个句子与其他7个句子之间的相似度,并删除平均相似度最低的3个句子。我们使用这5个句子作为最终生成的描述,并计算生成的描述与真实描述之间的相似度。
如果您想计算生成的描述与真实描述之间的相似度,请使用tool/get_sentence_simi.py脚本。例如:
cd tool
# 修改get_sentence_simi.py中的路径
python get_sentence_simi.py
您也可以使用tool/get_sentence_simi.py脚本来计算您自己数据的生成描述与真实描述之间的相似度。
结果
您可以在result文件夹中找到您的结果。
我们还在result文件夹中提供了我们的一个结果,即result.txt。
它使用提示"请用中文用一句话描述上面给出的音频中说话人的情感:",您可以使用训练提示之一或您自己的提示。
引用
如果您在研究中使用此仓库,请引用我们的论文:
@inproceedings{xu2024secap,
title={Secap: Speech emotion captioning with large language model},
author={Xu, Yaoxun and Chen, Hangting and Yu, Jianwei and Huang, Qiaochu and Wu, Zhiyong and Zhang, Shi-Xiong and Li, Guangzhi and Luo, Yi and Gu, Rongzhi},
booktitle={Proceedings of the AAAI Conference on Artificial Intelligence},
volume={38},
number={17},
pages={19323--19331},
year={2024}
}











