
 Github
Github 论文
论文DoLa: 通过对比层改进大型语言模型的事实性解码




论文"DoLa: 通过对比层改进大型语言模型的事实性解码"的代码
论文链接: https://arxiv.org/abs/2309.03883 作者: Yung-Sung Chuang $^\dagger$, Yujia Xie $^\ddagger$, Hongyin Luo $^\dagger$, Yoon Kim $^\dagger$, James Glass $^\dagger$, Pengcheng He $^\ddagger$ $^\dagger$ 麻省理工学院, $^\ddagger$ 微软
概述
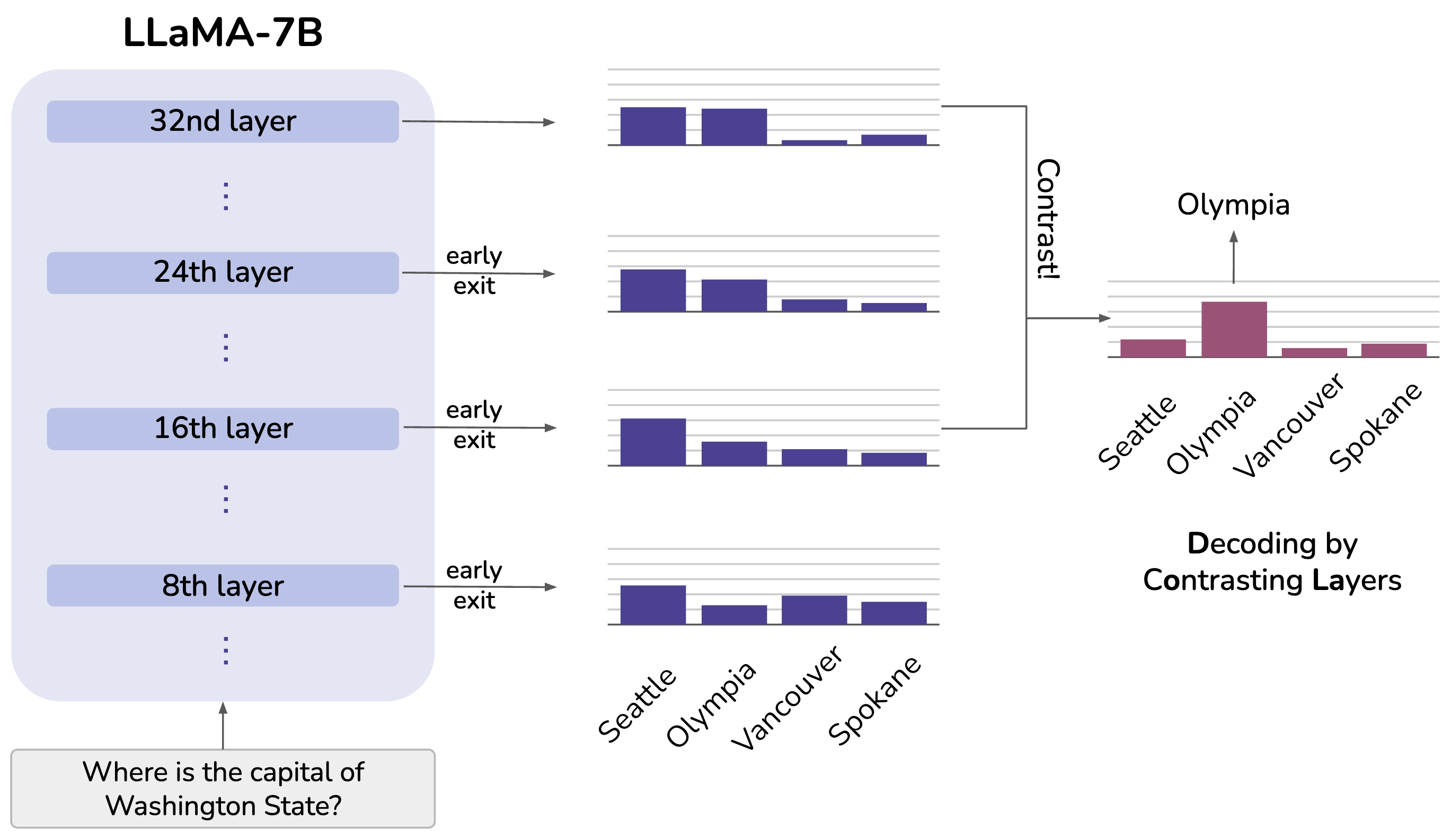
尽管大型语言模型(LLMs)具有令人印象深刻的能力,但它们容易产生幻觉,即生成偏离预训练期间所见事实的内容。我们提出了一种简单的解码策略,用于减少预训练LLMs的幻觉,该策略无需依赖检索外部知识或额外的微调。我们的方法通过对比将后层与前层投射到词汇空间所得到的logits差异来获得下一个标记的分布,利用了LLMs中的事实知识通常局限于特定的transformer层这一特性。我们发现这种通过对比层进行解码(DoLA)的方法能够更好地呈现事实知识并减少不正确事实的生成。DoLA在多项选择任务和开放式生成任务中持续提高真实性,例如将LLaMA系列模型在TruthfulQA上的表现提高了12-17个百分点,展示了其在使LLMs可靠生成真实事实方面的潜力。
设置
pip install -e transformers-4.28.1
pip install datasets
pip install accelerate
pip install openai # -> 仅用于truthfulqa和gpt4_eval
实验
参数
| 参数 | 示例 | 描述 |
|---|---|---|
--model-name | huggyllama/llama-7b | 指定要使用的模型,目前我们只支持LLaMA-v1。 |
--data-path | /path/to/dataset | 数据集文件或文件夹的路径。 |
--output-path | output-path.json | 存储输出结果的位置。 |
--num-gpus | 1 | 要使用的GPU数量,7B/13B/30B/65B模型大小分别对应1/2/4/8。 |
--max_gpu_memory | 27 | 要分配的最大GPU内存大小(以GiB为单位)。默认值:27(适用于32G V100)。 |
理解 --early-exit-layers
--early-exit-layers参数接受一个字符串,其中包含一系列由逗号分隔的层数,之间没有空格。通过指定不同数量的层,我们可以使模型以不同的模式进行解码。
| 指定的层数 | 示例(字符串) | 解码模式描述 |
|---|---|---|
| 1 | -1 | 从最后一层输出进行朴素解码。 |
| 2 | 16,32 | 使用第二个指定的层(即32)作为mature_layer,第一个指定的层(即16)作为premature_layer进行DoLa-static解码。 |
| >2 | 0,2,4,6,8,10,12,14,32 | 使用最后指定的层(即32)作为mature_layer,所有前面的层(即0,2,4,6,8,10,12,14)作为candidate_premature_layers进行DoLa解码。 |
FACTOR (多项选择)
请从 https://github.com/AI21Labs/factor 下载数据文件 wiki_factor.csv
基线
python factor_eval.py --model-name huggyllama/llama-7b --data-path /path/to/wiki_factor.csv --output-path output-path.json --num-gpus 1
python factor_eval.py --model-name huggyllama/llama-13b --data-path /path/to/wiki_factor.csv --output-path output-path.json --num-gpus 2
python factor_eval.py --model-name huggyllama/llama-30b --data-path /path/to/wiki_factor.csv --output-path output-path.json --num-gpus 4
python factor_eval.py --model-name huggyllama/llama-65b --data-path /path/to/wiki_factor.csv --output-path output-path.json --num-gpus 8
DoLa
python factor_eval.py --model-name huggyllama/llama-7b --early-exit-layers 0,2,4,6,8,10,12,14,32 --data-path /path/to/wiki_factor.csv --output-path output-path.json --num-gpus 1
python factor_eval.py --model-name huggyllama/llama-13b --early-exit-layers 0,2,4,6,8,10,12,14,16,18,40 --data-path /path/to/wiki_factor.csv --output-path output-path.json --num-gpus 2
python factor_eval.py --model-name huggyllama/llama-30b --early-exit-layers 0,2,4,6,8,10,12,14,16,18,60 --data-path /path/to/wiki_factor.csv --output-path output-path.json --num-gpus 4
python factor_eval.py --model-name huggyllama/llama-65b --early-exit-layers 0,2,4,6,8,10,12,14,16,18,80 --data-path /path/to/wiki_factor.csv --output-path output-path.json --num-gpus 8
TruthfulQA (多项选择)
--data-path应该是一个包含TruthfulQA.csv的文件夹。如果文件不存在,将自动下载。
基线
python tfqa_mc_eval.py --model-name huggyllama/llama-7b --data-path /path/to/data/folder --output-path output-path.json --num-gpus 1
python tfqa_mc_eval.py --model-name huggyllama/llama-13b --data-path /path/to/data/folder --output-path output-path.json --num-gpus 2
python tfqa_mc_eval.py --model-name huggyllama/llama-30b --data-path /path/to/data/folder --output-path output-path.json --num-gpus 4
python tfqa_mc_eval.py --model-name huggyllama/llama-65b --data-path /path/to/data/folder --output-path output-path.json --num-gpus 8
DoLa
python tfqa_mc_eval.py --model-name huggyllama/llama-7b --early-exit-layers 16,18,20,22,24,26,28,30,32 --data-path /path/to/data/folder --output-path output-path.json --num-gpus 1
python tfqa_mc_eval.py --model-name huggyllama/llama-13b --early-exit-layers 20,22,24,26,28,30,32,34,36,38,40 --data-path /path/to/data/folder --output-path output-path.json --num-gpus 2
python tfqa_mc_eval.py --model-name huggyllama/llama-30b --early-exit-layers 40,42,44,46,48,50,52,54,56,58,60 --data-path /path/to/data/folder --output-path output-path.json --num-gpus 4
python tfqa_mc_eval.py --model-name huggyllama/llama-65b --early-exit-layers 60,62,64,66,68,70,72,74,76,78,80 --data-path /path/to/data/folder --output-path output-path.json --num-gpus 8
TruthfulQA
为了评估TruthfulQA的开放式生成结果,我们需要通过OpenAI API微调两个GPT-3 curie模型:
openai api fine_tunes.create -t finetune_truth.jsonl -m curie --n_epochs 5 --batch_size 21 --learning_rate_multiplier 0.1
openai api fine_tunes.create -t finetune_info.jsonl -m curie --n_epochs 5 --batch_size 21 --learning_rate_multiplier 0.1
微调后,我们可以通过openai api fine_tunes.list | grep fine_tuned_model获取微调后的模型名称。
创建一个配置文件gpt3.config.json,如下所示:
{"gpt_info": "curie:ft-xxxxxxxxxx",
"gpt_truth": "curie:ft-xxxxxxxxxx",
"api_key": "xxxxxxx"}
为GPT-3评估添加参数--do-rating --gpt3-config gpt3.config.json。
基线
python tfqa_eval.py --model-name huggyllama/llama-7b --data-path /path/to/data/folder --output-path output-path.json --num-gpus 1 --do-rating --gpt3-config /path/to/gpt3.config.json
python tfqa_eval.py --model-name huggyllama/llama-13b --data-path /path/to/data/folder --output-path output-path.json --num-gpus 2 --do-rating --gpt3-config /path/to/gpt3.config.json
python tfqa_eval.py --model-name huggyllama/llama-30b --data-path /path/to/data/folder --output-path output-path.json --num-gpus 4 --do-rating --gpt3-config /path/to/gpt3.config.json
python tfqa_eval.py --model-name huggyllama/llama-65b --data-path /path/to/data/folder --output-path output-path.json --num-gpus 8 --do-rating --gpt3-config /path/to/gpt3.config.json
DoLa
python tfqa_eval.py --model-name huggyllama/llama-7b --early-exit-layers 16,18,20,22,24,26,28,30,32 --data-path /path/to/data/folder --output-path output-path.json --num-gpus 1 --do-rating --gpt3-config /path/to/gpt3.config.json
python tfqa_eval.py --model-name huggyllama/llama-13b --early-exit-layers 20,22,24,26,28,30,32,34,36,38,40 --data-path /path/to/data/folder --output-path output-path.json --num-gpus 2 --do-rating --gpt3-config /path/to/gpt3.config.json
python tfqa_eval.py --model-name huggyllama/llama-30b --early-exit-layers 40,42,44,46,48,50,52,54,56,58,60 --data-path /path/to/data/folder --output-path output-path.json --num-gpus 4 --do-rating --gpt3-config /path/to/gpt3.config.json
python tfqa_eval.py --model-name huggyllama/llama-65b --early-exit-layers 60,62,64,66,68,70,72,74,76,78,80 --data-path /path/to/data/folder --output-path output-path.json --num-gpus 8 --do-rating --gpt3-config /path/to/gpt3.config.json
GSM8K
我们使用GSM8K训练集的随机抽样子集作为StrategyQA和GSM8K的验证集。可以在这里下载文件。
--data-path参数应该是:
- 包含
gsm8k_test.jsonl的文件夹,否则文件将自动下载到您指定的文件夹。 - (仅适用于GSM8K)上面链接中可下载的
gsm8k-train-sub.jsonl文件的路径。
基线
python gsm8k_eval.py --model-name huggyllama/llama-7b --data-path /path/to/data/folder --output-path output-path.json --num-gpus 1
python gsm8k_eval.py --model-name huggyllama/llama-13b --data-path /path/to/data/folder --output-path output-path.json --num-gpus 2
python gsm8k_eval.py --model-name huggyllama/llama-30b --data-path /path/to/data/folder --output-path output-path.json --num-gpus 4
python gsm8k_eval.py --model-name huggyllama/llama-65b --data-path /path/to/data/folder --output-path output-path.json --num-gpus 8
DoLa
python gsm8k_eval.py --model-name huggyllama/llama-7b --early-exit-layers 0,2,4,6,8,10,12,14,32 --data-path /path/to/data/folder --output-path output-path.json --num-gpus 1
python gsm8k_eval.py --model-name huggyllama/llama-13b --early-exit-layers 0,2,4,6,8,10,12,14,16,18,40 --data-path /path/to/data/folder --output-path output-path.json --num-gpus 2
python gsm8k_eval.py --model-name huggyllama/llama-30b --early-exit-layers 0,2,4,6,8,10,12,14,16,18,60 --data-path /path/to/data/folder --output-path output-path.json --num-gpus 4
python gsm8k_eval.py --model-name huggyllama/llama-65b --early-exit-layers 0,2,4,6,8,10,12,14,16,18,80 --data-path /path/to/data/folder --output-path output-path.json --num-gpus 8
StrategyQA
--data-path参数应该是包含strategyqa_train.json的文件夹,否则文件将自动下载到您指定的文件夹。
基线
python strqa_eval.py --model-name huggyllama/llama-7b --data-path /path/to/data/folder --output-path output-path.json --num-gpus 1
python strqa_eval.py --model-name huggyllama/llama-13b --data-path /path/to/data/folder --output-path output-path.json --num-gpus 2
python strqa_eval.py --model-name huggyllama/llama-30b --data-path /path/to/data/folder --output-path output-path.json --num-gpus 4
python strqa_eval.py --model-name huggyllama/llama-65b --data-path /path/to/data/folder --output-path output-path.json --num-gpus 8
DoLa
python strqa_eval.py --model-name huggyllama/llama-7b --early-exit-layers 0,2,4,6,8,10,12,14,32 --data-path /path/to/data/folder --output-path output-path.json --num-gpus 1
python strqa_eval.py --model-name huggyllama/llama-13b --early-exit-layers 0,2,4,6,8,10,12,14,16,18,40 --data-path /path/to/data/folder --output-path output-path.json --num-gpus 2
python strqa_eval.py --model-name huggyllama/llama-30b --early-exit-layers 0,2,4,6,8,10,12,14,16,18,60 --data-path /path/to/data/folder --output-path output-path.json --num-gpus 4
python strqa_eval.py --model-name huggyllama/llama-65b --early-exit-layers 0,2,4,6,8,10,12,14,16,18,80 --data-path /path/to/data/folder --output-path output-path.json --num-gpus 8
GPT-4评估(Vicuna问答基准)
在GPT-4评估中,我们需要来自FastChat的问题文件。在以下命令中,我们假设您的FastChat仓库路径为$fastchat。
基线
python gpt4_judge_eval.py --model-name huggyllama/llama-7b --model-id llama-7b-baseline --question-file $fastchat/eval/table/question.jsonl --answer-file output-answer.jsonl --num-gpus 1
python gpt4_judge_eval.py --model-name huggyllama/llama-13b --model-id llama-13b-baseline --question-file $fastchat/eval/table/question.jsonl --answer-file output-answer.jsonl --num-gpus 2
python gpt4_judge_eval.py --model-name huggyllama/llama-30b --model-id llama-30b-baseline --question-file $fastchat/eval/table/question.jsonl --answer-file output-answer.jsonl --num-gpus 4
python gpt4_judge_eval.py --model-name huggyllama/llama-65b --model-id llama-65b-baseline --question-file $fastchat/eval/table/question.jsonl --answer-file output-answer.jsonl --num-gpus 8
DoLa
python gpt4_judge_eval.py --model-name huggyllama/llama-7b --early-exit-layers 0,2,4,6,8,10,12,14,32 --model-id llama-7b-dola --question-file $fastchat/eval/table/question.jsonl --answer-file output-answer.jsonl --num-gpus 1
python gpt4_judge_eval.py --model-name huggyllama/llama-13b --early-exit-layers 0,2,4,6,8,10,12,14,16,18,40 --model-id llama-13b-dola --question-file $fastchat/eval/table/question.jsonl --answer-file output-answer.jsonl --num-gpus 2
python gpt4_judge_eval.py --model-name huggyllama/llama-30b --early-exit-layers 0,2,4,6,8,10,12,14,16,18,60 --model-id llama-30b-dola --question-file $fastchat/eval/table/question.jsonl --answer-file output-answer.jsonl --num-gpus 4
python gpt4_judge_eval.py --model-name huggyllama/llama-65b --early-exit-layers 0,2,4,6,8,10,12,14,16,18,80 --model-id llama-65b-dola --question-file $fastchat/eval/table/question.jsonl --answer-file output-answer.jsonl --num-gpus 8
运行上述命令生成模型响应后,我们需要OpenAI API密钥来对不同解码结果的响应进行成对比较。
python $fastchat/eval/eval_gpt_review.py -q $fastchat/eval/table/question.jsonl -a output-answer-1.jsonl output-answer-2.jsonl -p $fastchat/eval/table/prompt.jsonl -r $fastchat/eval/table/reviewer.jsonl -o output-review-path.jsonl -k openai_api_key
有关GPT-4评估的更多详细信息,请查看vicuna-blog-eval。
参考仓库
- FastChat: https://github.com/lm-sys/FastChat
- ContrastiveDecoding: https://github.com/XiangLi1999/ContrastiveDecoding
- TruthfulQA: https://github.com/sylinrl/TruthfulQA
- zero_shot_cot: https://github.com/kojima-takeshi188/zero_shot_cot
- FederatedScope: https://github.com/alibaba/FederatedScope
引用
如果我们的论文对您的工作有帮助,请引用它!
@article{chuang2023dola,
title={DoLa: Decoding by Contrasting Layers Improves Factuality in Large Language Models},
author={Chuang, Yung-Sung and Xie, Yujia and Luo, Hongyin and Kim, Yoon and Glass, James and He, Pengcheng},
journal={arXiv preprint arXiv:2309.03883},
year={2023},
}











