
 访问官网
访问官网 Github
Github 论文
论文数值特征嵌入在表格深度学习中的应用(NeurIPS 2022)
:scroll: arXiv :package: Python包 :books: RTDL (表格深度学习的其他项目)
这是论文"表格深度学习中数值特征嵌入的应用"的官方实现。
摘要
一句话总结:在主干网络(如MLP、Transformer等)中混合之前,将原始标量连续特征转换为向量可以提高表格神经网络的下游性能。
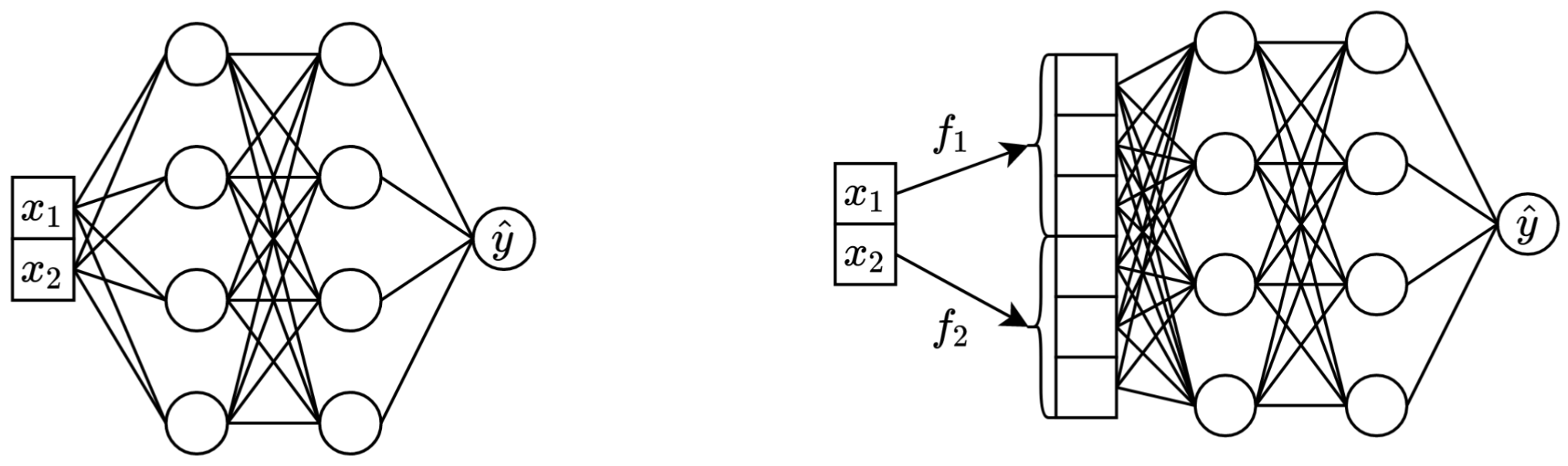
左:以两个连续特征作为输入的普通MLP。
右:同样的MLP,但现在对连续特征进行了嵌入。
更详细地说:
- 嵌入连续特征意味着在主干网络中混合之前,将它们从标量表示转换为向量表示,如上图所示。
- 事实证明,连续特征的嵌入可以(显著)提高表格深度学习模型的性能。
- 嵌入适用于任何常规的主干网络。
- 特别是,具有嵌入的简单MLP可以与重型Transformer模型相媲美,同时效率显著提高。
- 尽管在参数数量上有形式上的开销,但在实践中,嵌入在许多情况下是完全可以负担的。在足够大的数据集和/或足够多的特征数量和/或足够严格的延迟要求下,与嵌入相关的新开销可能会成为一个问题。
为什么嵌入有效?
严格来说,没有单一的解释。 显然,嵌入有助于处理与连续特征相关的各种挑战,并改善模型的整体优化性能。
特别是,不规则分布的连续特征(及其与标签的不规则联合分布)在现实世界的表格数据中很常见, 它们给传统的表格深度学习模型带来了重大的基本优化挑战。 一个很好的参考用于理解这一挑战 (以及通过转换输入空间来解决这些挑战的一个很好的例子) 是这篇论文 "傅里叶特征让网络在低维域中学习高频函数"。
然而,目前还不清楚不规则分布是否是嵌入有用的唯一原因。
Python包
Python包位于package/目录中,
是在实践中使用本文和进行未来工作的推荐方式。
文档其余部分:
如何探索指标和超参数
exp/目录包含了论文中使用的各种模型和数据集的大量结果和(调优的)超参数。
指标
例如,让我们探索MLP模型的指标。
首先,让我们加载报告(report.json文件):
import json
from pathlib import Path
import pandas as pd
df = pd.json_normalize([
json.loads(x.read_text())
for x in Path('exp').glob('mlp/*/0_evaluation/*/report.json')
])
现在,对于每个数据集,让我们计算在所有随机种子上平均的测试分数:
print(df.groupby('config.data.path')['metrics.test.score'].mean().round(3))
输出与论文中的表3完全一致:
config.data.path
data/adult 0.854
data/california -0.495
data/churn 0.856
data/covtype 0.964
data/fb-comments -5.686
data/gesture 0.632
data/higgs-small 0.720
data/house -32039.399
data/microsoft -0.747
data/otto 0.818
data/santander 0.912
Name: metrics.test.score, dtype: float64
超参数
上述方法也可以用于探索超参数,以直观了解不同算法的典型超参数值。 例如,这是如何计算MLP模型的中位数调优学习率:
[!注意] 对于某些算法(例如MLP、MLP-LR、MLP-PLR),更新的项目提供了更多可以以类似方式探索的结果。例如,请参见 关于TabR的这篇论文。
[!警告] 谨慎使用此方法。 在研究超参数值时:
- 注意异常值。
- 查看原始未聚合的值,以直观了解典型值。
- 对于高级概览,绘制分布图和/或计算多个分位数。
print(df[df['config.seed'] == 0]['config.training.lr'].quantile(0.5))
# 输出: 0.0002716544410603358
如何重现结果
[!重要]
本节较长。 使用GitHub或文本编辑器中的"大纲"功能以获取本节的概览。
设置环境
软件
准备工作:
- 根据您的设置,您可能需要更改下面的CUDA相关命令和设置
- 确保
/usr/local/cuda-11.1/bin始终在您的PATH环境变量中 - 安装conda
export PROJECT_DIR=<仓库根目录的绝对路径>
# 示例: export PROJECT_DIR=/home/myusername/repositories/num-embeddings
git clone https://github.com/yandex-research/tabular-dl-num-embeddings $PROJECT_DIR
cd $PROJECT_DIR
conda create -n num-embeddings python=3.9.7
conda activate num-embeddings
pip install torch==1.10.1+cu111 -f https://download.pytorch.org/whl/torch_stable.html
pip install -r requirements.txt
# 如果以下命令不成功,请更新conda
conda env config vars set PYTHONPATH=${PYTHONPATH}:${PROJECT_DIR}
conda env config vars set PROJECT_DIR=${PROJECT_DIR}
# 以下命令将":/usr/local/cuda-11.1/lib64"附加到LD_LIBRARY_PATH;
# 如果您的LD_LIBRARY_PATH已经包含其他CUDA的路径,那么"="后的内容
# 应该是"<不包含您的cuda路径的LD_LIBRARY_PATH>:/usr/local/cuda-11.1/lib64"
conda env config vars set LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:/usr/local/cuda-11.1/lib64
conda env config vars set CUDA_HOME=/usr/local/cuda-11.1
conda env config vars set CUDA_ROOT=/usr/local/cuda-11.1
# (可选)获取使用cmd+y切换暗模式的快捷方式
conda install nodejs
jupyter labextension install jupyterlab-theme-toggle
conda 停用
conda 激活 num-embeddings
数据
许可证:通过下载我们的数据集,您接受其所有组件的许可。 我们不会在这些许可之外施加任何新的限制。 您可以在论文中找到来源列表。
cd $PROJECT_DIR
wget "https://www.dropbox.com/s/r0ef3ij3wl049gl/data.tar?dl=1" -O num_embeddings_data.tar
tar -xvf num_embeddings_data.tar
如何复现结果
以下代码复现了在加利福尼亚房价数据集上使用MLP的结果。其他算法和数据集的流程完全相同。
# 如果要使用GPU,必须明确设置CUDA_VISIBLE_DEVICES
export CUDA_VISIBLE_DEVICES="0"
# 创建"官方"配置的副本
cp exp/mlp/california/0_tuning.toml exp/mlp/california/1_tuning.toml
# 运行调优(在GPU上大约需要30-60分钟)
python bin/tune.py exp/mlp/california/1_tuning.toml
# 使用15个不同的随机种子评估单个模型
python bin/evaluate.py exp/mlp/california/1_tuning 15
# 评估集成模型(默认为三个大小为五的集成)
python bin/ensemble.py exp/mlp/california/1_evaluation
# 然后使用bin/results.ipynb查看获得的结果
了解仓库
代码概览
代码组织如下:
bintrain4.py用于神经网络(实现了论文中的所有嵌入和骨干网络)xgboost_.py用于XGBoostcatboost_.py用于CatBoosttune.py用于调优evaluate.py用于评估ensemble.py用于集成results.ipynb用于总结结果datasets.py用于构建数据集分割synthetic.py用于生成GBDT友好的合成数据集train1_synthetic.py用于合成数据的实验
lib包含bin中程序使用的通用工具exp包含实验配置和结果(指标、调优后的配置等)。嵌套文件夹的名称遵循论文中的名称(例如:exp/mlp-plr对应论文中的MLP-PLR模型)。package包含此论文的Python包
技术说明
- 运行脚本时必须明确设置
CUDA_VISIBLE_DEVICES - 对于保存和加载配置,使用
lib.dump_config和lib.load_config而不是直接使用TOML库
运行脚本
运行脚本的常见模式是:
python bin/my_script.py a/b/c.toml
其中a/b/c.toml是输入配置文件(配置)。输出将位于a/b/c。配置结构通常遵循bin/my_script.py中的Config类。
还有一些脚本接受命令行参数而不是配置(例如bin/{evaluate.py,ensemble.py})。
train0.py vs train1.py vs train3.py vs train4.py
复现结果时需要全部使用,但未来工作只需要train4.py,因为:
bin/train1.py实现了bin/train0.py的所有功能及更多bin/train3.py实现了bin/train1.py的所有功能及更多bin/train4.py实现了bin/train3.py的所有功能及更多
要查看某个实验使用了哪个脚本,请检查相应调优配置的"program"字段。例如,这是加利福尼亚房价数据集上MLP的调优配置:exp/mlp/california/0_tuning.toml。该配置表明使用了bin/train0.py。这意味着exp/mlp/california/0_evaluation中的配置专门与bin/train0.py兼容。要验证这一点,您可以将其中一个复制到单独的位置并传递给bin/train0.py:
mkdir exp/tmp
cp exp/mlp/california/0_evaluation/0.toml exp/tmp/0.toml
python bin/train0.py exp/tmp/0.toml
ls exp/tmp/0
如何引用
@inproceedings{gorishniy2022embeddings,
title={On Embeddings for Numerical Features in Tabular Deep Learning},
author={Yury Gorishniy and Ivan Rubachev and Artem Babenko},
booktitle={{NeurIPS}},
year={2022},
}











