
 访问官网
访问官网 Github
Githubstable-diffusion-webui-prompt-travel
在潜在空间中在提示词之间旅行以生成伪动画,这是AUTOMATIC1111/stable-diffusion-webui的扩展脚本。






尝试对条件提示词的隐藏向量进行插值,以生成看似连续的图像序列,或者说是伪动画。😀 不仅仅是提示词!我们还支持非提示词条件,请阅读 => README_ext.md~
⚠ 我们成立了插件反馈QQ群:616795645(赤狐屿),欢迎提出建议、意见、报告bug等(w ⚠ 我们现在有一个QQ聊天群(616795645),非常欢迎任何建议、讨论和bug报告!!
ℹ 说实话,我想可能可以通过这个来制作ppt童话绘本甚至本子……
ℹ 聪明的用法:先手工盲搜两张好看的图(只有提示词差异),然后再尝试在其间travel :lolipop:
⚠ 记得在设置页勾选"总是保存所有生成的图片",否则上采样和保存中间图片将无法工作。 ⚠ 记得在设置页勾选"总是保存所有生成的图片",否则上采样与保存中间图片将无法工作。
更新日志
⚪ 兼容性
最新版本v3.1与以下版本同步并测试:
- AUTOMATIC1111/stable-diffusion-webui:版本
v1.5.1,标签v1.5.1 - Mikubill/sd-webui-controlnet:版本
v1.1.229,提交eceeec7a7e
⚪ 功能
- 2023/07/31:
v3.1支持 SDXL v1.0 模型 - 2023/07/05:
v3.0使用 sd-webuiv1.4.0回调重新实现核心功能;这个新实现会更慢,但与其他扩展的兼容性更好 - 2023/04/13:
v2.7在 controlnet-travel 中添加 RIFE,跳过融合(实验性) - 2023/03/31:
v2.6为后处理工具链添加一个 tkinter GUI - 2023/03/30:
v2.5添加 controlnet-travel 脚本(实验性),在提示条件而非提示词之间进行插值,感谢来自 sd-webui-controlnet 的代码基础 - 2023/02/14:
v2.3集成 depth-image-io 的基本功能,用于深度图到图像模型 - 2023/01/27:
v2.2添加 'slerp' 线性插值方法 - 2023/01/22:
v2.1再次添加实验性的 'replace' 模式,这不是平滑插值 - 2023/01/20:
v2.0添加可选的外部后处理管道以大幅提高平滑度,非常感谢 Real-ESRGAN 和 RIFE!! - 2023/01/16:
v1.5添加放大选项(问题 #12);添加 'embryo' 起源,复现 stable-diffusion-animation 的想法,但不包括 FILM 支持(问题 #11) - 2023/01/12:
v1.4由于 webui 代码变更,移除 'replace' 和 'grad' 模式支持 - 2022/12/11:
v1.3以更"连续"的方式工作,想法借鉴自 deforum('genesis' 选项) - 2022/11/14:
v1.2通过替换词元嵌入进行遍历('replace' 模式) - 2022/11/13:
v1.1通过优化条件进行遍历('grad' 模式) - 2022/11/10:
v1.0在条件/非条件上线性插值('linear' 模式)
⚪ 修复
- 2023/12/29: 修复错误的 ffmpeg 环境变量,更新 controlnet 至
v1.1.424 - 2023/07/05: 更新 controlnet 至
v1.1.229 - 2023/04/30: 更新 controlnet 至
v1.1.116 - 2023/03/29:
v2.4修复脚本钩子的错误,现在可以正常与额外网络和 sd-webui-controlnet 一起工作 - 2023/01/31: 跟进 webui 的更新(问题 #14:
ImportError: cannot import name 'single_sample_to_image') - 2023/01/28: 跟进 webui 的更新,额外网络重构
- 2023/01/16:
v1.5在条件长度不匹配时应用零填充(问题 #10:RuntimeError: The size of tensor a (77) must match the size of tensor b (154) at non-singleton dimension 0),演示文件名中的拼写错误 - 2023/01/12:
v1.4跟进 webui 的更新(问题 #9:AttributeError: 'FrozenCLIPEmbedderWithCustomWords' object has no attribute 'process_text') - 2022/12/13:
#bdd8bed修复当负面提示为空时不工作的问题(问题 #6:neg_prompts[-1] IndexError: List index out of range) - 2022/11/27:
v1.2-fix2跟进 webui 的更新(错误ImportError: FrozenCLIPEmbedderWithCustomWords) - 2022/11/20:
v1.2-fix1跟进 webui 的更新(错误AttributeError: p.all_negative_prompts[0])
⚠ 本脚本可能不会支持调度语法(即:[prompt:prompt:number]),因为在可变条件上进行插值需要采样器级别的跟踪,这很难维护 :(
⚠ 由于 denoising_strength 的一些内在概念/逻辑冲突,本脚本可能无法与 hires.fix 一起工作,你可以选择先进行批量放大,然后再进行批量图像到图像处理。
它是如何工作的?
- 在提示/负面提示框中输入多行,每行称为一个阶段
- 逐个生成图像,在一个阶段向下一个阶段过渡(忽略批量配置)
- 逐步改变处理后的输入提示
- 冻结所有其他设置(
步数、采样器、CFG系数、种子等) - 注意只有主要
种子会在整个过程中被强制固定,你仍可以设置子种子 = -1以允许更多变化
- 冻结所有其他设置(
- 导出视频!
- 按照后处理流程获得更好的结果 👌
⚪ 文本生成图像
| 采样器\生成方式 | 固定 | 连续 | 胚胎 |
|---|---|---|---|
| Eular a |  |  |  |
| DDIM |  |  |  |
⚪ 图像生成图像
| 采样器\生成方式 | 固定 | 连续 | 胚胎 |
|---|---|---|---|
| Eular a |  |  |  |
| DDIM |  |  |  |
后处理流程(以i2i-f-ddim为例):
| 无后处理 | 有后处理 |
|---|---|
|  |
其他内容:
| 图像生成图像的参考图像 | 解码后的胚胎图像 以 i2i-e-euler_a和胚胎步数=8为例 |
|---|---|
 |  |
⚪ 支持ControlNet
| 使用 ControlNet(深度)进行提示词旅行 | 使用 ControlNet(深度)进行旅行 |
|---|---|
 |  |
上面示例的运行配置:
正面提示词:
(((杰作))), 高分辨率, ((男孩)), 儿童, 猫耳朵, 白发, 红眼睛, 黄色铃铛, 红色斗篷, 赤脚, 天使, [飞行], 埃及风格
((杰作)), 高分辨率, ((女孩)), 萝莉, 猫耳朵, 浅蓝色头发, 红眼睛, 魔法杖, 赤脚, [奔跑]
负面提示词:
(((不适合工作场合的内容))), 丑陋,重复,病态,残缺,变性人,跨性别,变异,畸形,长脖子,解剖不正确,比例不当,多余的手臂,多余的腿,毁容,超过2个乳头,畸形,变异,雌雄同体,画面外,多余的肢体,缺少手臂,缺少腿,画得很差的手,画得很差的脸,变异,画得很差,身体长,多个乳房,克隆的脸,比例严重失调,变异的手,糟糕的手,糟糕的脚,长脖子,缺少肢体,畸形的肢体,畸形的手,手指融合,手指过多,额外的手指,缺少手指,多出的数字,较少的数字,变异的手和手指,低分辨率,文字,错误,裁剪,最差质量,低质量,普通质量,JPEG压缩痕迹,签名,水印,用户名,模糊,文字字体,女性焦点,画得很差,变形,画得很差的脸,(多余的腿:1.3),(多余的手指:1.2),画面外
步数:15
CFG缩放:7
Clip跳过:1
种子:114514
尺寸:512 x 512
模型哈希:animefull-final-pruned.ckpt
超网络:(这是我的秘密 :)
选项
-
提示词:(字符串列表)
-
负面提示词:(字符串列表)
- 输入多行提示词文本
- 我们将每行提示词称为一个阶段,通常你至少需要2行文本才能开始旅行
- 如果正面提示词数量不等于负面提示词数量,较短的那个的最后一项会重复以匹配较长的那个
-
模式:(分类)
线性:对CLIP输出的条件/非条件进行线性插值替换:逐步替换CLIP输出- 替换维度:(分类)
词元:按词元向量通道:按通道向量随机:按点元素
- 替换顺序:(分类)
相似:从最相似的开始(L1距离)不同:从最不同的开始随机:随机顺序
- 替换维度:(分类)
胚胎:预先去噪几步,然后通过线性插值从共同胚胎孵化一组图像
-
步数:(整数或整数列表)
- 两个阶段之间插值的图像数量
- 如果是整数,则为恒定的旅行步数
- 如果是整数列表,长度应与
阶段数-1匹配,用逗号分隔,例如:12, 24, 36
-
起源:(分类),每个图像帧的先验
固定:在txt2img流程中从纯噪声开始,或在img2img流程中从给定的相同参考图像开始连续:从上一个生成的图像开始(这将强制txt2img从第二帧开始实际变为img2img)胚胎:从相同的半去噪图像开始,参见=> 它是如何工作的?- (实验性)它只处理2行提示词,并且不对负面提示词进行插值 :(
-
起源额外参数
- 去噪强度:(浮点数),img2img流程中的去噪强度(用于
连续) - 胚胎步数:(整数或浮点数),孵化共同胚胎的步数(用于
胚胎)- 如果 >= 1,视为步数
- 如果 < 1,视为总步数的比例
- 去噪强度:(浮点数),img2img流程中的去噪强度(用于
-
视频_*
- fps:(浮点数),视频的帧率,设置为
0以禁用文件保存 - 格式:(分类),导出视频文件格式
- 填充:(整数),重复开始/结束帧,提供一个进入/退出时间
- 选择:(字符串),在填充之前使用Python切片语法挑选帧(例如:设置
::2只获取偶数帧,设置:-1删除最后一帧)
- fps:(浮点数),视频的帧率,设置为
安装
最简单的安装方法是:
- 转到webui中的"扩展"选项卡,切换到"从URL安装"选项卡
- 将 https://github.com/Kahsolt/stable-diffusion-webui-prompt-travel.git 粘贴到"扩展的git仓库URL"中,然后点击安装
- (可选)你需要重启webui以安装依赖项,否则将无法生成视频文件 手动安装:
- 将此仓库文件夹复制到 https://github.com/AUTOMATIC1111/stable-diffusion-webui 的 'extensions' 文件夹中
- (可选)重启 webui
后处理流程
距离真正流畅和高分辨率的动画还有两个步骤,即图像超分辨率和视频帧插值(参见下面的第三方工具)。
⚠ 媒体数据处理本质上是资源消耗型的,这也不是 webui 的工作或职责,因此我们将其分离出来。😃
一次性设置
⚪ 自动安装(Windows)
- 运行
cd tools & install.cmd - 故障排除
- 如果遇到任何文件系统访问错误,如
Access denied.,请尝试重新运行,直到看到没有错误的Done!😂 - 如果遇到关于
curl schannel ... Unknown error ... certificate.的 SSL 错误,由于某些 SSL 安全原因下载器无法工作,请转为手动安装...
- 如果遇到任何文件系统访问错误,如
- 你将在 tools 文件夹下安装四个组件:Busybox、Real-ESRGAN、RIFE 和 FFmpeg
⚪ 手动安装(Windows/Linux/Mac)
ℹ 首先了解 tools 文件夹布局 => tools/README.txt
ℹ 如果你确实想把工具放在其他地方,修改 tools/link.cmd 中的路径并运行 cd tools & link.cmd 😉
对于 Windows:
- 下载 Busybox
- 下载 Real-ESRGAN(例如:
realesrgan-ncnn-vulkan-20220424-windows.zip)- (可选)下载有趣的单独模型检查点(例如:
realesr-animevideov3.pth)
- (可选)下载有趣的单独模型检查点(例如:
- 下载 rife-ncnn-vulkan 包(例如:
rife-ncnn-vulkan-20221029-windows.zip) - 下载 FFmpeg 二进制文件(例如:
ffmpeg-release-full-shared.7z或ffmpeg-git-full.7z)
对于 Linux/Mac:
- 下载 Real-ESRGAN 和 rife-ncnn-vulkan,按照
tools文件夹布局放置它们,手动对可执行文件应用chmod 755 ffmpeg可以在你的应用商店或包管理器中轻松找到,运行类似apt install ffmpeg;不需要在tools文件夹下链接它
每次运行
⚪ tkinter GUI(Windows/Linux/Mac)
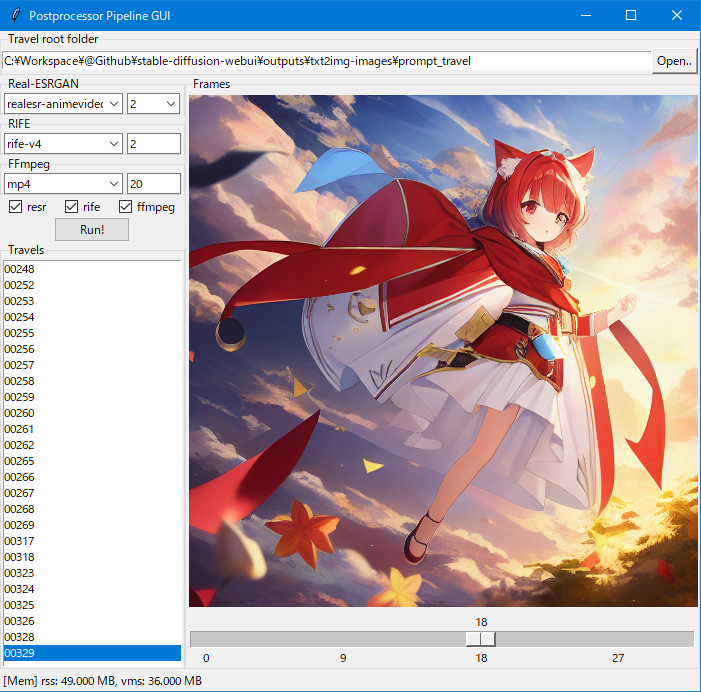
对于 Windows:
- 运行
manager.cmd,启动 webui 的 python 虚拟环境 - 运行 DOSKEY
install(仅设置一次) - 运行 DOSKEY
run
对于 Linux/Mac:
- 运行
../../venv/Scripts/activate,启动 webui 的 python 虚拟环境 - 运行
pip install -r requirements.txt(仅设置一次) - 运行
python manager.py
ℹ 在右键弹出菜单中查找使用帮助信息~
⚪ cmd 脚本(Windows)- 已弃用
- 在 postprocess-config.cmd 中检查参数
- 选择一种方式启动 😃
- 从命令行运行
postprocess.cmd path/to/<image_folder> - 将任何图像文件夹拖放到
postprocess.cmd图标上
- 从命令行运行
- 处理完成后,将自动启动资源管理器定位到名为
synth.mp4的生成文件
相关项目
⚪ 启发此仓库的扩展
- sd-webui-controlnet(各种图像条件):https://github.com/Mikubill/sd-webui-controlnet
- depth-image-io(自定义深度图到图像):https://github.com/AnonymousCervine/depth-image-io-for-SDWebui
- animator(图像到图像):https://github.com/Animator-Anon/animator_extension
- sd-webui-riffusion(音乐生成):https://github.com/enlyth/sd-webui-riffusion
- sd-animation(半去噪 + FILM):
- deforum(图像到图像 + 深度模型):https://github.com/deforum-art/deforum-for-automatic1111-webui
- seed-travel(变化种子):https://github.com/yownas/seed_travel
⚪ 第三方工具
- 图像超分辨率
- ESRGAN:
- ESRGAN:https://github.com/xinntao/ESRGAN
- Real-ESRGAN:https://github.com/xinntao/Real-ESRGAN
- Real-ESRGAN-ncnn-vulkan(推荐):https://github.com/xinntao/Real-ESRGAN-ncnn-vulkan
- ESRGAN:
- 视频帧插值
- FILM(推荐):https://github.com/google-research/frame-interpolation
- RIFE:
- ECCV2022-RIFE:https://github.com/megvii-research/ECCV2022-RIFE
- rife-ncnn-vulkan(推荐):https://github.com/nihui/rife-ncnn-vulkan
- Squirrel-RIFE:https://github.com/Justin62628/Squirrel-RIFE
- Practical-RIFE:https://github.com/hzwer/Practical-RIFE
- GNU 工具包
- BusyBox:https://www.busybox.net/
- Windows 版 BusyBox:https://frippery.org/busybox/
- FFmpeg:https://ffmpeg.org/
- BusyBox:https://www.busybox.net/
⚪ 我的其他实验性玩具扩展
- vid2vid(视频到视频):https://github.com/Kahsolt/stable-diffusion-webui-vid2vid
- hires-fix-progressive(高分辨率修复的渐进版本):https://github.com/Kahsolt/stable-diffusion-webui-hires-fix-progressive
- sonar(k_diffusion 采样器):https://github.com/Kahsolt/stable-diffusion-webui-sonar
- size-travel(图像尺寸的 X-Y 图变体):https://github.com/Kahsolt/stable-diffusion-webui-size-travel
作者:Armit 日期:2022/11/10











