
 Github
Github Huggingface
Huggingface 论文
论文LaVIT:赋予大型语言模型理解和生成视觉内容的能力
这是多模态大型语言模型LaVIT和Video-LaVIT的官方代码库。LaVIT项目旨在利用LLM的卓越能力来处理视觉内容。所提出的预训练策略支持在统一框架下进行视觉理解和生成。
新闻和更新
-
2024.04.21🚀🚀🚀 我们已在HuggingFace上发布了Video-LaVIT的预训练权重,并提供了推理代码。 -
2024.02.05🌟🌟🌟 我们提出了Video-LaVIT:一种有效的多模态预训练方法,使LLM能够在统一框架下理解和生成视频内容。 -
2024.01.15👏👏👏 LaVIT已被ICLR 2024接收! -
2023.10.17🚀🚀🚀 我们在HuggingFace上发布了LaVIT的预训练权重,并提供了用于多模态理解和生成的推理代码。
介绍
LaVIT和Video-LaVIT是通用多模态基础模型,继承了LLM成功的学习范式:以自回归方式预测下一个视觉/文本标记。LaVIT系列工作的核心设计包括视觉标记器和解标记器。视觉标记器旨在将非语言视觉内容(如图像、视频)转换为LLM可读的离散标记序列,就像外语一样。解标记器将LLM生成的离散标记恢复为连续的视觉信号。
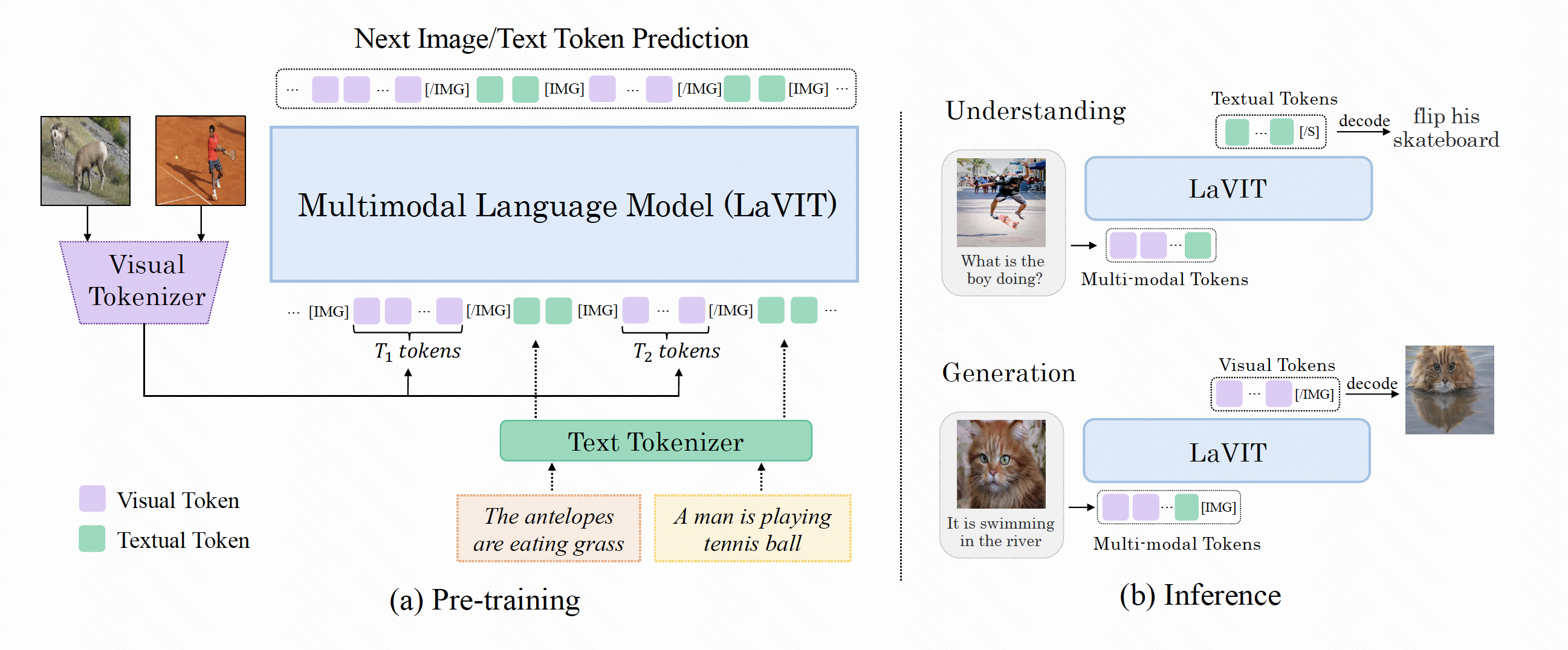
LaVIT流程
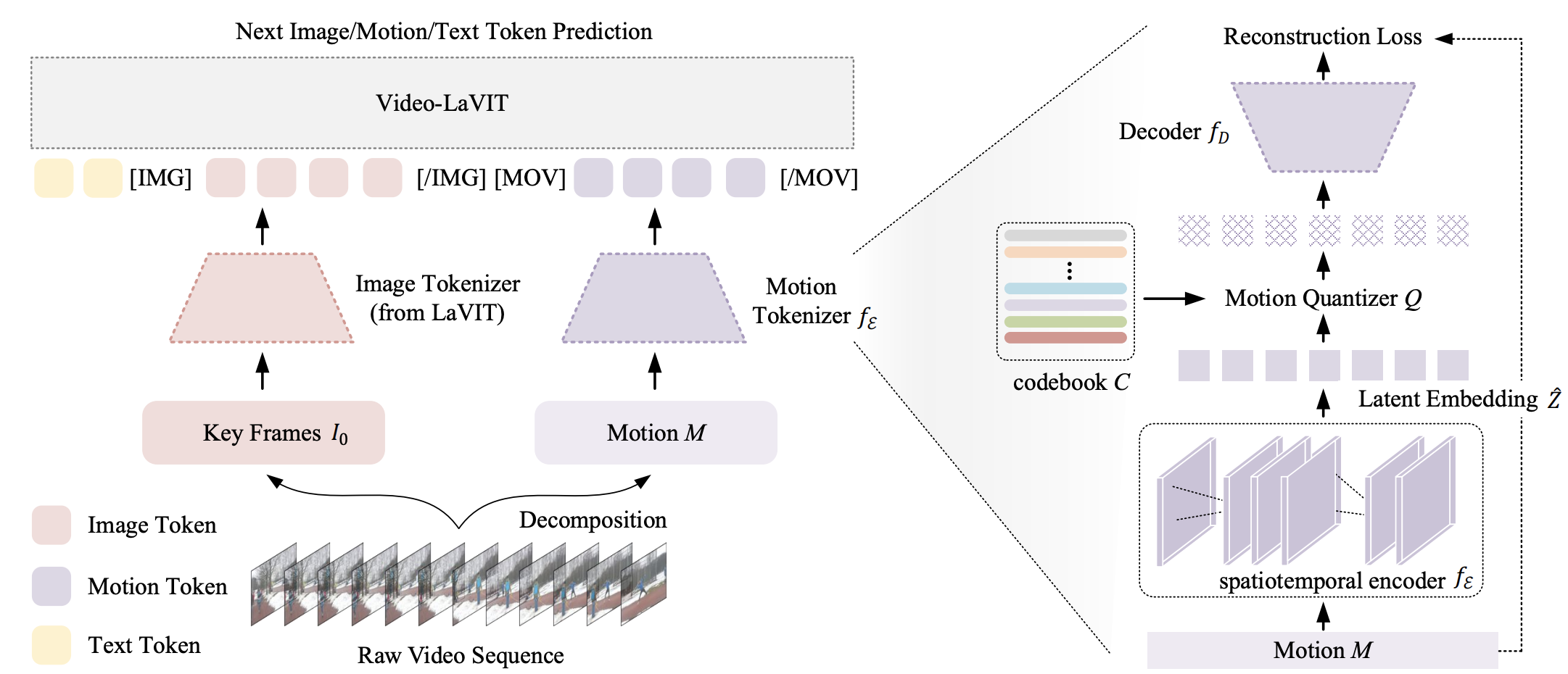
Video-LaVIT流程
预训练后,LaVIT和Video-LaVIT可以支持:
- 阅读图像和视频内容,生成描述,回答问题。
- 文本到图像、文本到视频和图像到视频的生成。
- 通过多模态提示进行生成。
引用
如果本代码库对您的研究有帮助,请考虑给它加星并在您的出版物中引用LaVIT。
@article{jin2023unified,
title={Unified Language-Vision Pretraining in LLM with Dynamic Discrete Visual Tokenization},
author={Jin, Yang and Xu, Kun and Xu, Kun and Chen, Liwei and Liao, Chao and Tan, Jianchao and Mu, Yadong and others},
journal={arXiv preprint arXiv:2309.04669},
year={2023}
}
@article{jin2024video,
title={Video-LaVIT: Unified Video-Language Pre-training with Decoupled Visual-Motional Tokenization},
author={Jin, Yang and Sun, Zhicheng and Xu, Kun and Chen, Liwei and Jiang, Hao and Huang, Quzhe and Song, Chengru and Liu, Yuliang and Zhang, Di and Song, Yang and others},
journal={arXiv preprint arXiv:2402.03161},
year={2024}
}











