
 访问官网
访问官网 Github
Github语言分割-万物
语言分割-万物是一个开源项目,它结合了实例分割和文本提示的力量,为图像中的特定对象生成蒙版。该项目基于最近发布的Meta模型segment-anything和GroundingDINO检测模型构建,是一个易于使用且有效的对象检测和图像分割工具。
特点
- 零样本文本到边界框方法用于对象检测
- 集成GroundingDINO检测模型
- 使用Lightning AI应用平台轻松部署
- 可自定义文本提示以进行精确对象分割
入门
先决条件
- Python 3.7或更高版本
- torch(已测试2.0版本)
- torchvision
安装
pip install torch torchvision
pip install -U git+https://github.com/luca-medeiros/lang-segment-anything.git
或者 克隆仓库并安装所需包:
git clone https://github.com/luca-medeiros/lang-segment-anything && cd lang-segment-anything
pip install torch torchvision
pip install -e .
或使用Conda
从environment.yml文件创建Conda环境:
conda env create -f environment.yml
# 激活新环境:
conda activate lsa
Docker安装
构建并运行镜像。
```
docker build --tag lang-segment-anything:latest .
docker run --gpus all -it lang-segment-anything:latest
```
如果你想要一个共享文件夹,可以使用-v <主机源目录>:<容器目标目录>添加卷,例如:-v ./data:/workspace/data
使用方法
运行Lightning AI应用:
lightning run app app.py
作为库使用:
from PIL import Image
from lang_sam import LangSAM
model = LangSAM()
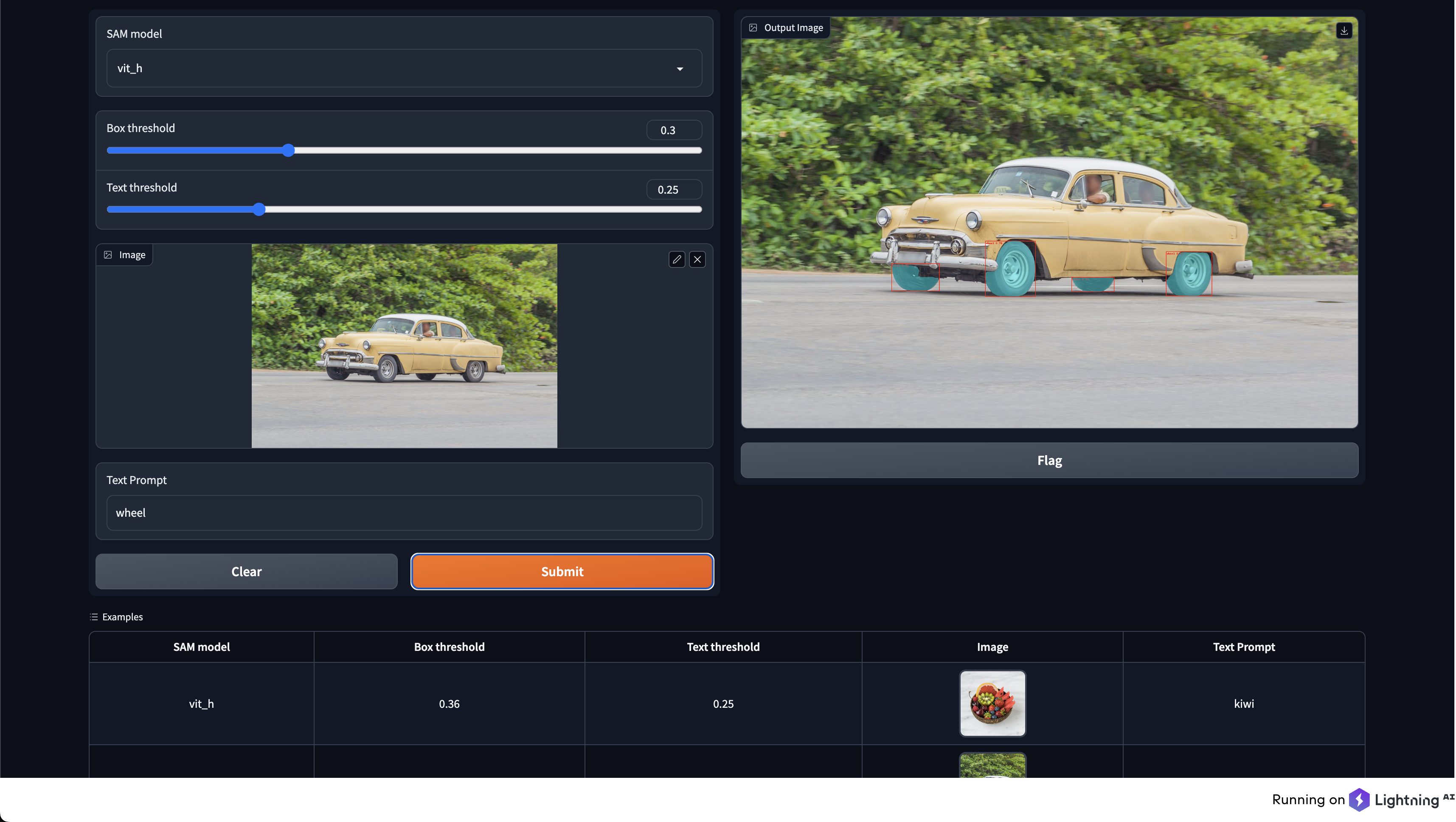
image_pil = Image.open("./assets/car.jpeg").convert("RGB")
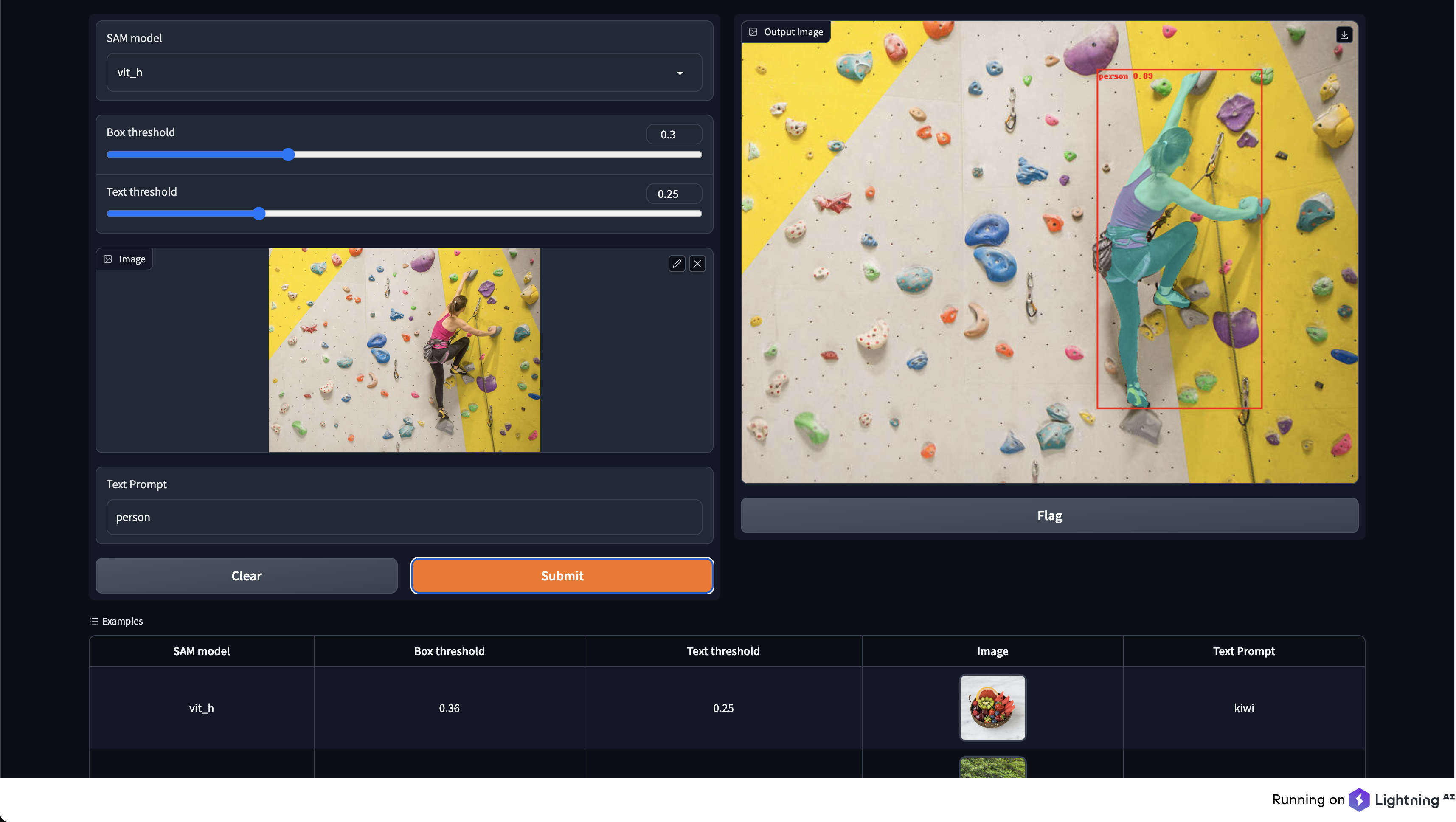
text_prompt = "wheel"
masks, boxes, phrases, logits = model.predict(image_pil, text_prompt)
使用自定义检查点:
首先下载模型检查点。
from PIL import Image
from lang_sam import LangSAM
model = LangSAM("<模型类型>", "<检查点路径>")
image_pil = Image.open("./assets/car.jpeg").convert("RGB")
text_prompt = "wheel"
masks, boxes, phrases, logits = model.predict(image_pil, text_prompt)
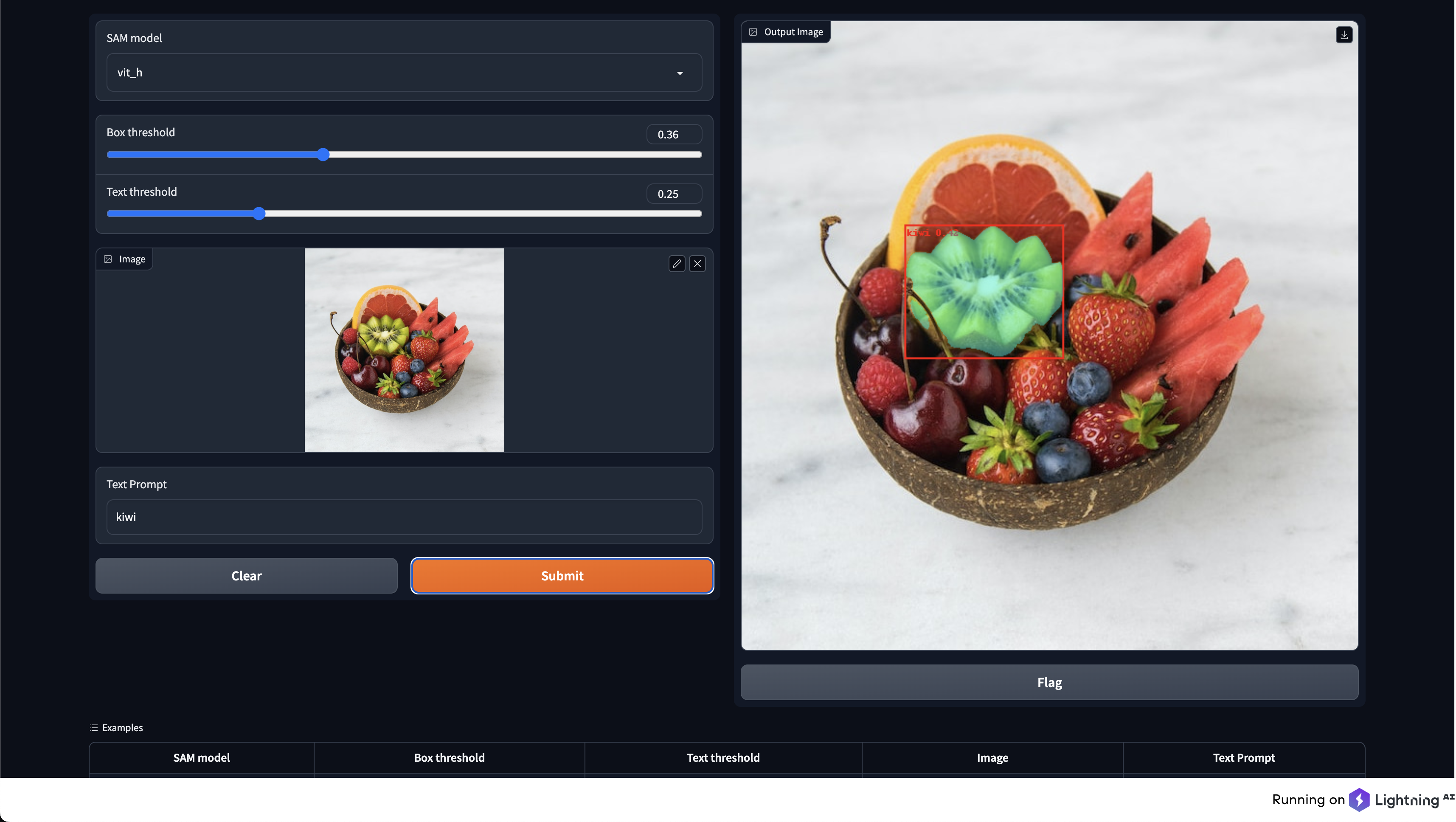
示例
路线图
本项目的未来目标包括:
-
FastAPI集成:为进一步简化部署,我们计划在项目中添加FastAPI代码,使用户更容易部署和与模型交互。
-
标注流程:我们想创建一个标注流程,允许用户输入文本提示和图像,并接收已标注的实例分割输出。这将帮助用户高效地生成结果,以供进一步分析和训练。
-
实现CLIP版本:为(可能)增强模型的能力和性能,我们将探索集成OpenAI的CLIP模型。这可能会提供更好的语言理解,并可能产生更好的实例分割结果。
致谢
本项目基于以下仓库:
许可
本项目采用Apache 2.0许可证











