
 Github
Github Huggingface
Huggingface 论文
论文EfficientViT:高分辨率密集预测的多尺度线性注意力模型(论文,海报)
新闻
如果您有兴趣获取更新,请在此处加入我们的邮件列表。
- [2024/07/10] EfficientViT作为主干网络应用于Grounding DINO 1.5 Edge中,用于高效开放集目标检测。
- [2024/07/10] EfficientViT-SAM在MedficientSAM中使用,该模型在CVPR 2024笔记本电脑上医学图像分割挑战赛中获得第一名。
- [2024/07/10] 基于FPGA的EfficientViT加速器:链接。
- [2024/04/23] 我们发布了EfficientViT-SAM的训练代码。
- [2024/04/06] EfficientViT-SAM被eLVM@CVPR'24接收。
- [2024/03/19] EfficientViT-SAM在线演示可用:https://evitsam.hanlab.ai/。
- [2024/02/07] 我们发布了EfficientViT-SAM,这是第一个匹配/超越SAM-ViT-H零样本性能的加速SAM模型,提供了最先进的性能效率权衡。
- [2023/11/20] EfficientViT在NVIDIA Jetson生成式AI实验室中可用。
- [2023/09/12] EfficientViT被MIT主页和MIT新闻报道。
- [2023/07/18] EfficientViT被ICCV 2023接收。
关于EfficientViT模型
EfficientViT是一个新的ViT模型系列,用于高效的高分辨率密集预测视觉任务。EfficientViT的核心构建块是一个轻量级、多尺度的线性注意力模块,它仅使用硬件高效的操作就实现了全局感受野和多尺度学习,使EfficientViT对TensorRT友好,适合GPU部署。
第三方实现/集成
入门
conda create -n efficientvit python=3.10
conda activate efficientvit
conda install -c conda-forge mpi4py openmpi
pip install -r requirements.txt
EfficientViT应用
Segment Anything

| 模型 | 分辨率 | COCO mAP | LVIS mAP | 参数量 | MACs | Jetson Orin 延迟 (bs1) | A100 吞吐量 (bs16) | 检查点 |
|---|---|---|---|---|---|---|---|---|
| EfficientViT-SAM-L0 | 512x512 | 45.7 | 41.8 | 34.8M | 35G | 8.2ms | 762 图像/秒 | 链接 |
| EfficientViT-SAM-L1 | 512x512 | 46.2 | 42.1 | 47.7M | 49G | 10.2ms | 638 图像/秒 | 链接 |
| EfficientViT-SAM-L2 | 512x512 | 46.6 | 42.7 | 61.3M | 69G | 12.9ms | 538 图像/秒 | 链接 |
| EfficientViT-SAM-XL0 | 1024x1024 | 47.5 | 43.9 | 117.0M | 185G | 22.5ms | 278 图像/秒 | 链接 |
| EfficientViT-SAM-XL1 | 1024x1024 | 47.8 | 44.4 | 203.3M | 322G | 37.2ms | 182 图像/秒 | 链接 |
表1:所有EfficientViT-SAM变体的总结。 COCO mAP和LVIS mAP是使用ViTDet预测的边界框作为提示来测量的。端到端Jetson Orin延迟和A100吞吐量是使用TensorRT和fp16测量的。
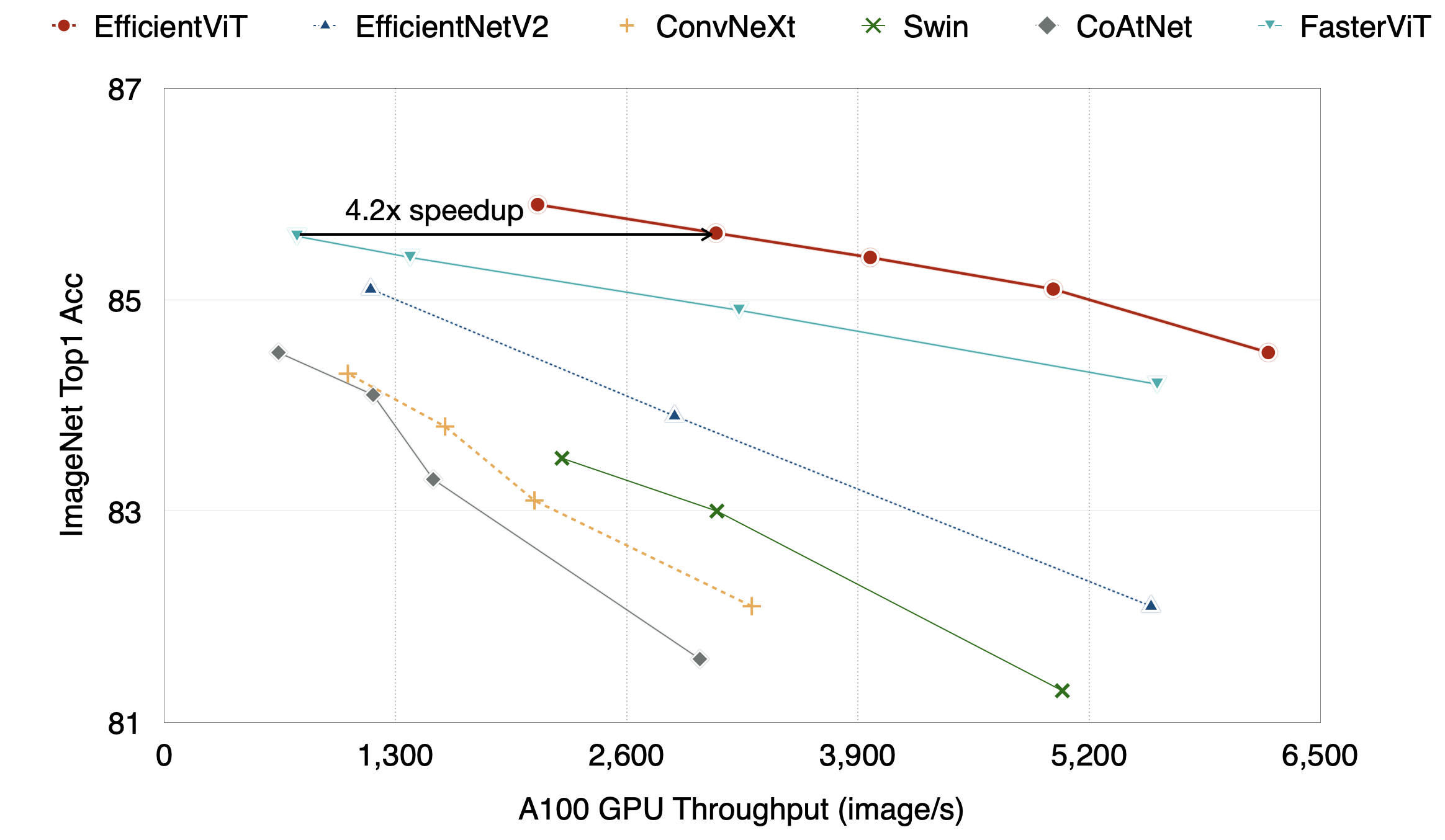
图像分类
语义分割

演示
- GazeSAM:结合EfficientViT-SAM与视线估计

联系方式
待办事项
- ImageNet预训练模型
- 分割预训练模型
- ImageNet训练代码
- EfficientViT L系列,专为云端设计
- 用于segment anything的EfficientViT
- 用于图像生成的EfficientViT
- 用于CLIP的EfficientViT
- 用于超分辨率的EfficientViT
- 分割训练代码
引用
如果EfficientViT对您的研究有用或相关,请通过引用我们的论文来认可我们的贡献:
@article{cai2022efficientvit,
title={Efficientvit: Enhanced linear attention for high-resolution low-computation visual recognition},
author={Cai, Han and Gan, Chuang and Han, Song},
journal={arXiv preprint arXiv:2205.14756},
year={2022}
}











