
 Github
Github Huggingface
Huggingface 文档
文档 论文
论文
一个用于在异构表格数据上构建神经网络模型的模块化深度学习框架。
![]()
![]()
![]()
![]()
PyTorch Frame 是 PyTorch 的深度学习扩展,专为包含数值、类别、时间、文本和图像等不同列类型的异构表格数据设计。它提供了一个模块化框架,用于实现现有和未来的方法。该库包含最先进模型的方法、用户友好的小批量加载器、基准数据集以及自定义数据集成接口。
PyTorch Frame 让表格数据的深度学习研究变得更加普及,既适合新手也适合专家。我们的目标是:
-
促进表格数据的深度学习: 历史上,基于树的模型(如 GBDT)在表格学习方面表现出色,但存在一些明显的局限性,例如与下游模型的集成困难,以及处理复杂列类型(如文本、序列和嵌入)的能力。深度表格模型有望解决这些局限性。我们的目标是通过模块化实现并支持多样的列类型,来促进表格数据的深度学习研究。
-
与大型语言模型等多样化模型架构集成: PyTorch Frame 支持与各种不同的架构集成,包括大型语言模型。使用任何下载的模型或嵌入 API 端点,您可以为文本数据生成嵌入,并与其他复杂语义类型一起使用深度学习模型进行训练。我们支持以下(但不限于):




库亮点
PyTorch Frame 直接构建在 PyTorch 之上,确保现有 PyTorch 用户能够顺利过渡。主要特性包括:
- 多样化列类型:
PyTorch Frame 支持跨各种列类型的学习:
numerical、categorical、multicategorical、text_embedded、text_tokenized、timestamp、image_embedded和embedding。详细教程请参见此处。 - 模块化模型设计: 支持模块化深度学习模型实现,促进代码重用、清晰编码和实验灵活性。更多详情请参见架构概览。
- 模型 实现了许多最先进的深度表格模型以及强大的 GBDT(XGBoost、CatBoost 和 LightGBM),并支持超参数调优。
- 数据集: 提供了一系列可直接使用的表格数据集。同时支持自定义数据集以解决您自己的问题。 我们对深度表格模型与 GBDT 进行了基准测试。
- PyTorch 集成: 与其他 PyTorch 库无缝集成,便于 PyTorch Frame 与下游 PyTorch 模型的端到端训练。例如,通过与 PyTorch 图神经网络库 PyG 集成,我们可以对关系数据库进行深度学习。更多信息请参见 RelBench 和示例代码(进行中)。
架构概览
PyTorch Frame 中的模型遵循 FeatureEncoder、TableConv 和 Decoder 的模块化设计,如下图所示:
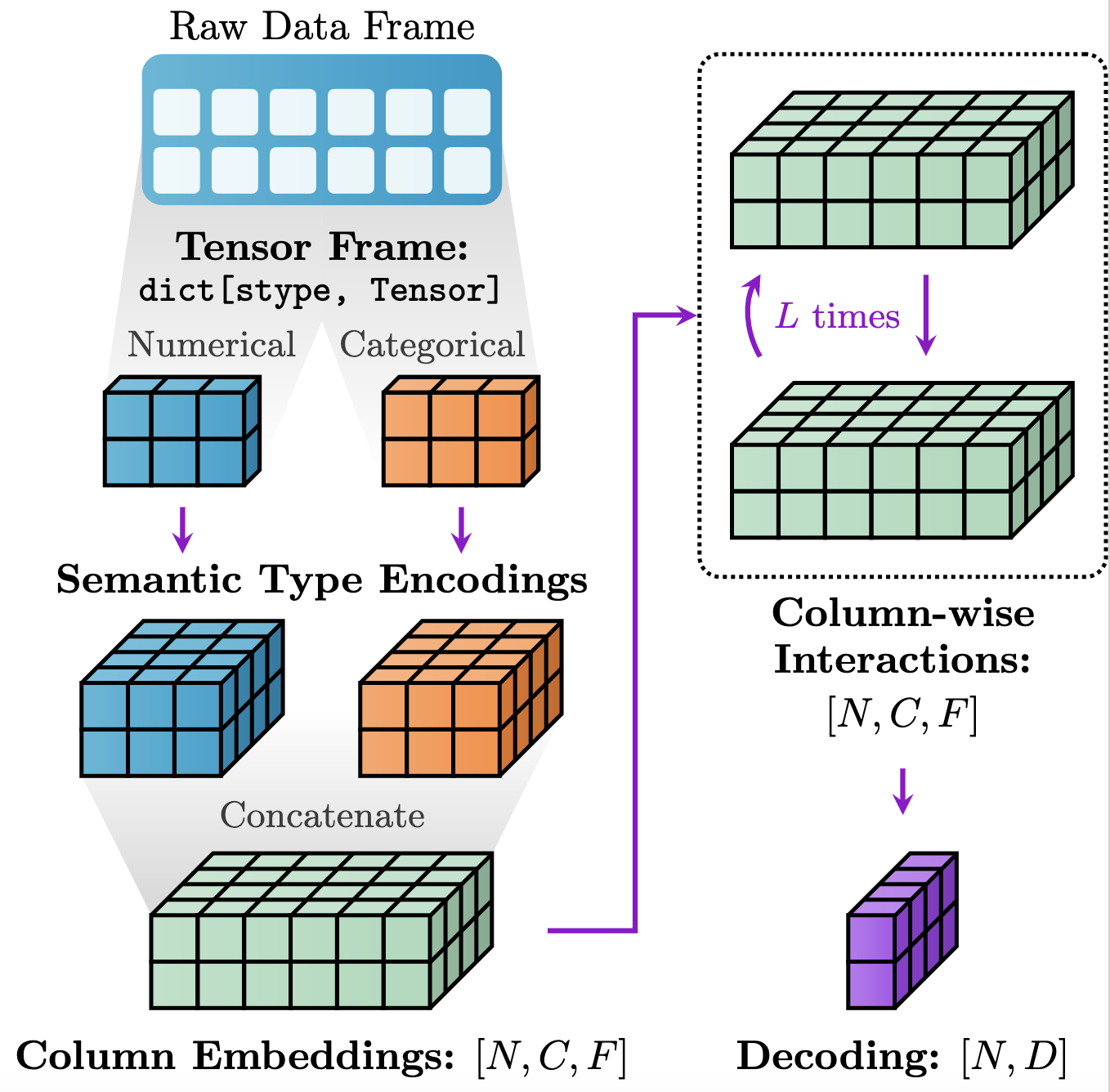
本质上,这种模块化设置使用户能够轻松尝试各种架构:
Materialization处理将原始 pandasDataFrame转换为适合 PyTorch 训练和建模的TensorFrame。FeatureEncoder将TensorFrame编码为大小为[batch_size, num_cols, channels]的隐藏列嵌入。TableConv对隐藏嵌入进行列间交互建模。Decoder为每行生成嵌入/预测。
快速上手
在这个快速上手中,我们将展示如何仅用几行代码就能轻松创建和训练一个深度表格模型。
构建并训练您自己的深度表格模型
作为示例,我们将按照 PyTorch Frame 的模块化架构实现一个简单的 ExampleTransformer。
在下面的示例中:
self.encoder将输入的TensorFrame映射到大小为[batch_size, num_cols, channels]的嵌入。self.convs迭代地将大小为[batch_size, num_cols, channels]的嵌入转换为相同大小的嵌入。self.decoder将大小为[batch_size, num_cols, channels]的嵌入池化为[batch_size, out_channels]。
from torch import Tensor
from torch.nn import Linear, Module, ModuleList
from torch_frame import TensorFrame, stype
from torch_frame.nn.conv import TabTransformerConv
from torch_frame.nn.encoder import (
EmbeddingEncoder,
LinearEncoder,
StypeWiseFeatureEncoder,
)
class ExampleTransformer(Module):
def __init__(
self,
channels, out_channels, num_layers, num_heads,
col_stats, col_names_dict,
):
super().__init__()
self.encoder = StypeWiseFeatureEncoder(
out_channels=channels,
col_stats=col_stats,
col_names_dict=col_names_dict,
stype_encoder_dict={
stype.categorical: EmbeddingEncoder(),
stype.numerical: LinearEncoder()
},
)
self.convs = ModuleList([
TabTransformerConv(
channels=channels,
num_heads=num_heads,
) for _ in range(num_layers)
])
self.decoder = Linear(channels, out_channels)
def forward(self, tf: TensorFrame) -> Tensor:
x, _ = self.encoder(tf)
for conv in self.convs:
x = conv(x)
out = self.decoder(x.mean(dim=1))
return out
要准备数据,我们可以快速实例化一个预定义的数据集并创建一个与 PyTorch 兼容的数据加载器,如下所示:
from torch_frame.datasets import Yandex
from torch_frame.data import DataLoader
dataset = Yandex(root='/tmp/adult', name='adult')
dataset.materialize()
train_dataset = dataset[:0.8]
train_loader = DataLoader(train_dataset.tensor_frame, batch_size=128,
shuffle=True)
然后,我们只需按照标准PyTorch训练流程来优化模型参数。就这么简单!
import torch
import torch.nn.functional as F
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = ExampleTransformer(
channels=32,
out_channels=dataset.num_classes,
num_layers=2,
num_heads=8,
col_stats=train_dataset.col_stats,
col_names_dict=train_dataset.tensor_frame.col_names_dict,
).to(device)
optimizer = torch.optim.Adam(model.parameters())
for epoch in range(50):
for tf in train_loader:
tf = tf.to(device)
pred = model.forward(tf)
loss = F.cross_entropy(pred, tf.y)
optimizer.zero_grad()
loss.backward()
已实现的深度表格模型
以下是目前支持的深度表格模型列表:
- Trompt,来自Chen等人:Trompt: 更优的表格数据深度神经网络(ICML 2023)[示例]
- FTTransformer,来自Gorishniy等人:重新审视表格数据的深度学习模型(NeurIPS 2021)[示例]
- ResNet,来自Gorishniy等人:重新审视表格数据的深度学习模型(NeurIPS 2021)[示例]
- TabNet,来自Arık等人:TabNet:注意力可解释的表格学习(AAAI 2021)[示例]
- ExcelFormer,来自Chen等人:ExcelFormer:一个在表格数据上胜过GBDT的神经网络 [示例]
- TabTransformer,来自Huang等人:TabTransformer:使用上下文嵌入的表格数据建模 [示例]
此外,我们还为想要将模型性能与GBDT进行比较的用户实现了XGBoost、CatBoost和LightGBM的示例,这些示例使用Optuna进行超参数调优。
基准测试
我们在多种规模和任务类型的公共数据集上对最近的表格深度学习模型与GBDT进行了基准测试。
下图展示了各种模型在小型回归数据集上的性能,其中行代表模型名称,列代表数据集索引(这里我们有13个数据集)。有关分类和更大数据集的更多结果,请查看基准测试文档。
| 模型名称 | 数据集0 | 数据集1 | 数据集2 | 数据集3 | 数据集4 | 数据集5 | 数据集6 | 数据集7 | 数据集8 | 数据集9 | 数据集10 | 数据集11 | 数据集12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| XGBoost | 0.250±0.000 | 0.038±0.000 | 0.187±0.000 | 0.475±0.000 | 0.328±0.000 | 0.401±0.000 | 0.249±0.000 | 0.363±0.000 | 0.904±0.000 | 0.056±0.000 | 0.820±0.000 | 0.857±0.000 | 0.418±0.000 |
| CatBoost | 0.265±0.000 | 0.062±0.000 | 0.128±0.000 | 0.336±0.000 | 0.346±0.000 | 0.443±0.000 | 0.375±0.000 | 0.273±0.000 | 0.881±0.000 | 0.040±0.000 | 0.756±0.000 | 0.876±0.000 | 0.439±0.000 |
| LightGBM | 0.253±0.000 | 0.054±0.000 | 0.112±0.000 | 0.302±0.000 | 0.325±0.000 | 0.384±0.000 | 0.295±0.000 | 0.272±0.000 | 0.877±0.000 | 0.011±0.000 | 0.702±0.000 | 0.863±0.000 | 0.395±0.000 |
| Trompt | 0.261±0.003 | 0.015±0.005 | 0.118±0.001 | 0.262±0.001 | 0.323±0.001 | 0.418±0.003 | 0.329±0.009 | 0.312±0.002 | OOM | 0.008±0.001 | 0.779±0.006 | 0.874±0.004 | 0.424±0.005 |
| ResNet | 0.288±0.006 | 0.018±0.003 | 0.124±0.001 | 0.268±0.001 | 0.335±0.001 | 0.434±0.004 | 0.325±0.012 | 0.324±0.004 | 0.895±0.005 | 0.036±0.002 | 0.794±0.006 | 0.875±0.004 | 0.468±0.004 |
| FTTransformerBucket | 0.325±0.008 | 0.096±0.005 | 0.360±0.354 | 0.284±0.005 | 0.342±0.004 | 0.441±0.003 | 0.345±0.007 | 0.339±0.003 | OOM | 0.105±0.011 | 0.807±0.010 | 0.885±0.008 | 0.468±0.006 |
| ExcelFormer | 0.262±0.004 | 0.099±0.003 | 0.128±0.000 | 0.264±0.003 | 0.331±0.003 | 0.411±0.005 | 0.298±0.012 | 0.308±0.007 | OOM | 0.011±0.001 | 0.785±0.011 | 0.890±0.003 | 0.431±0.006 |
| FTTransformer | 0.335±0.010 | 0.161±0.022 | 0.140±0.002 | 0.277±0.004 | 0.335±0.003 | 0.445±0.003 | 0.361±0.018 | 0.345±0.005 | OOM | 0.106±0.012 | 0.826±0.005 | 0.896±0.007 | 0.461±0.003 |
| TabNet | 0.279±0.003 | 0.224±0.016 | 0.141±0.010 | 0.275±0.002 | 0.348±0.003 | 0.451±0.007 | 0.355±0.030 | 0.332±0.004 | 0.992±0.182 | 0.015±0.002 | 0.805±0.014 | 0.885±0.013 | 0.544±0.011 |
| TabTransformer | 0.624±0.003 | 0.229±0.003 | 0.369±0.005 | 0.340±0.004 | 0.388±0.002 | 0.539±0.003 | 0.619±0.005 | 0.351±0.001 | 0.893±0.005 | 0.431±0.001 | 0.819±0.002 | 0.886±0.005 | 0.545±0.004 |
我们可以看到,一些最新的深度表格模型能够达到与强大的GBDT相当的模型性能(尽管训练速度慢5-100倍)。使深度表格模型在更少计算资源下表现更好是未来研究的一个富有成果的方向。
我们还在一个带有一列文本的真实世界表格数据集(葡萄酒评论)上对不同的文本编码器进行了基准测试。下表显示了性能结果:
| 测试准确率 | 方法 | 模型名称 | 来源 |
|---|---|---|---|
| 0.7926 | 预训练 | sentence-transformers/all-distilroberta-v1 (1.25亿参数) | Hugging Face |
| 0.7998 | 预训练 | embed-english-v3.0 (维度大小: 1024) | Cohere |
| 0.8102 | 预训练 | text-embedding-ada-002 (维度大小: 1536) | OpenAI |
| 0.8147 | 预训练 | voyage-01 (维度大小: 1024) | Voyage AI |
| 0.8203 | 预训练 | intfloat/e5-mistral-7b-instruct (70亿参数) | Hugging Face |
| 0.8230 | LoRA微调 | DistilBERT (6600万参数) | Hugging Face |
Hugging Face文本编码器的基准测试脚本在这个文件中,其他文本编码器的基准测试脚本在这个文件中。
安装
PyTorch Frame支持Python 3.8到Python 3.11版本。
pip install pytorch_frame
查看安装指南了解其他安装选项。
引用
如果您在工作中使用了PyTorch Frame,请引用我们的论文(Bibtex如下)。
@article{hu2024pytorch,
title={PyTorch Frame: A Modular Framework for Multi-Modal Tabular Learning},
author={Hu, Weihua and Yuan, Yiwen and Zhang, Zecheng and Nitta, Akihiro and Cao, Kaidi and Kocijan, Vid and Leskovec, Jure and Fey, Matthias},
journal={arXiv preprint arXiv:2404.00776},
year={2024}
}











