
 访问官网
访问官网 Github
Github 文档
文档



由Samuel Pfrommer制作,作为伯克利Somayeh Sojoudi小组的一部分。

对您网络中发生的事情感到好奇?TorchExplorer是一个简单的工具,允许您在训练过程中交互式地检查网络中每个nn.Module的输入、输出、参数和梯度。它与weights and biases集成,也可以作为独立解决方案在本地运行。如果您的用例适合(请参见下面的限制),尝试起来非常简单:
torchexplorer.setup() # 在wandb.init()之前调用一次,独立使用时不需要
wandb.init()
model = ...
torchexplorer.watch(model, backend='wandb') # 或 'standalone'
# 训练循环...
安装
安装需要一个外部的graphviz依赖,大多数包管理器都应该可以使用。
Linux.
sudo apt-get install libgraphviz-dev graphviz
pip install torchexplorer
如果pygraphvizwheel构建因找不到Python.h而失败,您必须安装Python头文件,如这里所述。
Mac.
brew install graphviz
pip install torchexplorer
如果出现关于#include "graphviz/cgraph.h"的错误,对于Apple silicon,以下方法对我有效:
python -m pip install \
--global-option=build_ext \
--global-option="-I$(brew --prefix graphviz)/include/" \
--global-option="-L$(brew --prefix graphviz)/lib/" \
pygraphviz
使用方法
更多示例,请参见/tests和/examples。
查看模型结构。 TorchExplorer的模型结构交互式视图本身也很有用(不包括直方图等附加功能)。这里有一个独立的例子,展示了如何获取ResNet18的交互式视图。将鼠标悬停在特定节点上会显示输入/输出张量形状和模块参数。您可以通过交互式演示感受一下它的样子。
import torch
import torchvision
import torchexplorer
model = torchvision.models.resnet18(pretrained=False)
dummy_X = torch.randn(5, 3, 32, 32)
# 仅记录输入/输出和参数直方图,如果不想要这些,设置log=[]。
torchexplorer.watch(model, log_freq=1, log=['io', 'params'], backend='standalone')
# 要同时记录梯度,设置 log = ['io', 'io_grad', 'params', 'params_grad'](默认)。
# 这不适用于原地操作(参见README.md中的"常见错误#1")。
# 因此,我们必须禁用原地激活,并忽略具有残差连接的模块。
# 这里我们使用随机数据在未经训练的模型上,所以梯度并不是很有用。
# residual_class = torchvision.models.resnet.BasicBlock
# torchexplorer.watch(
# model, log_freq=1, disable_inplace=True,
# log=['io', 'io_grad', 'params', 'params_grad'],
# ignore_io_grad_classes=[residual_class], backend='standalone'
# )
# 进行一次前向和后向传播
model(dummy_X).sum().backward()
# 您的模型将在 http://localhost:8080 上可用
可视化中间张量。 TorchExplorer自动捕获任何模块的输入/输出。使用torchexplorer.attach,您还可以将任何中间张量记录到界面。
import torch
from torch import nn
import torchexplorer
class AttachModule(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(10, 10)
self.fc2 = nn.Linear(10, 10)
def forward(self, x):
x = self.fc1(x)
x = torchexplorer.attach(x, self, 'intermediate')
return self.fc2(x)
model = AttachModule()
dummy_X = torch.randn(5, 10)
torchexplorer.watch(model, log_freq=1, backend='standalone')
model(dummy_X).sum().backward()
# 您的模型将在 http://localhost:8080 上可用
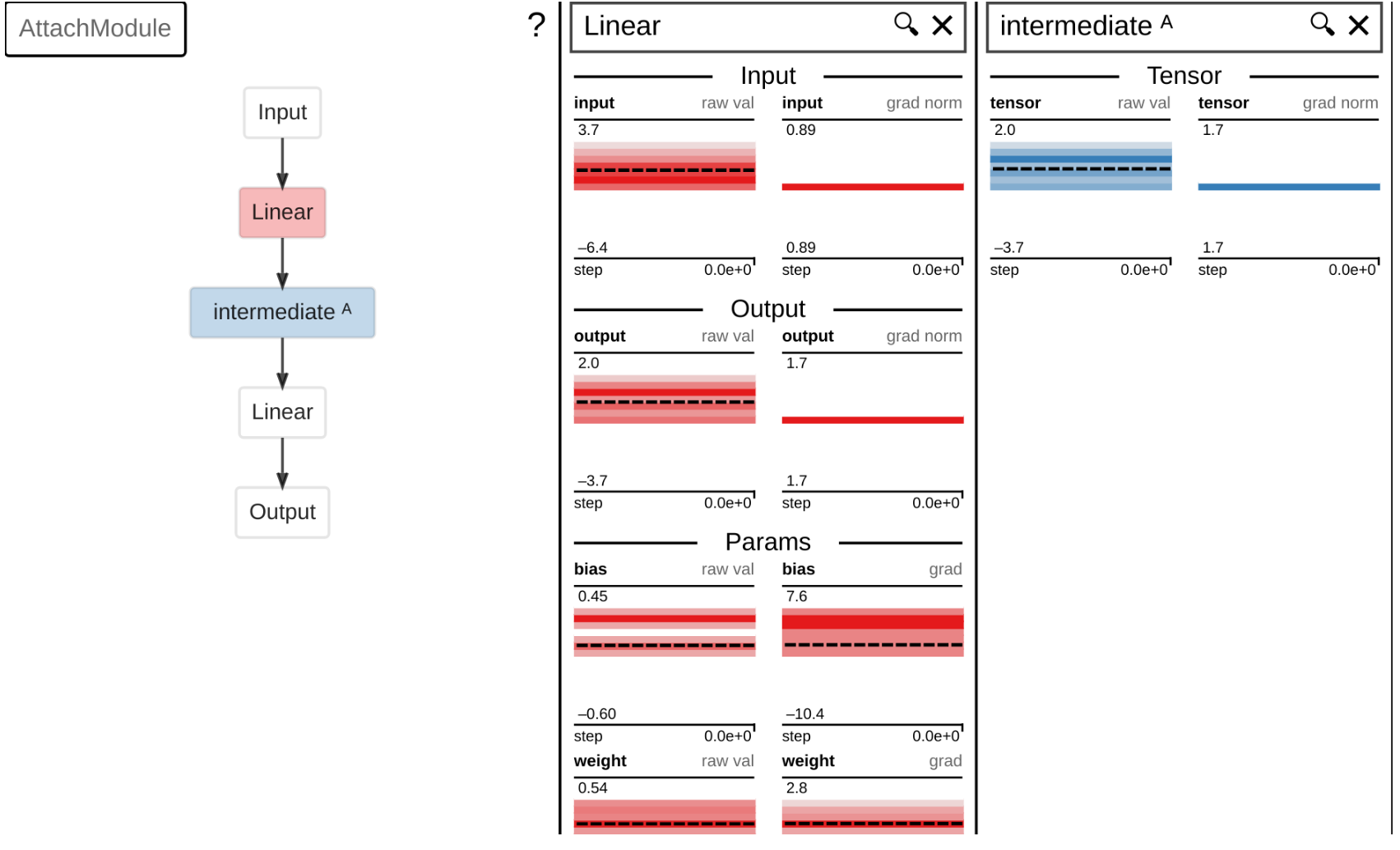
更多调试用例。 TorchExplorer旨在成为一个通用工具,用于查看网络中发生的事情——有点类似于电子学中的示波器。本节列出了一些潜在的用例。
- 检查您的模型是否存在梯度消失/爆炸问题。
- 检查特定模块的输入是否分布良好(如果不是,添加一个归一化层)。
- 捕获错误,如在模块输出可能为负时使用
ReLU非线性作为最后一层。 - 对于多个子模块的输出被组合的情况,检查梯度是否更多地流向其中一个。
- 如果一个模块有多个输入,通过相对梯度范数大小来判断哪个输入更重要。
- 确保潜在空间/嵌入分布看起来健康(例如,VAE潜在变量近似正态分布)。
- 使用
torchexplorer.attach来查看梯度是主要通过跳跃连接还是主网络路径流动。
用户界面
探索器
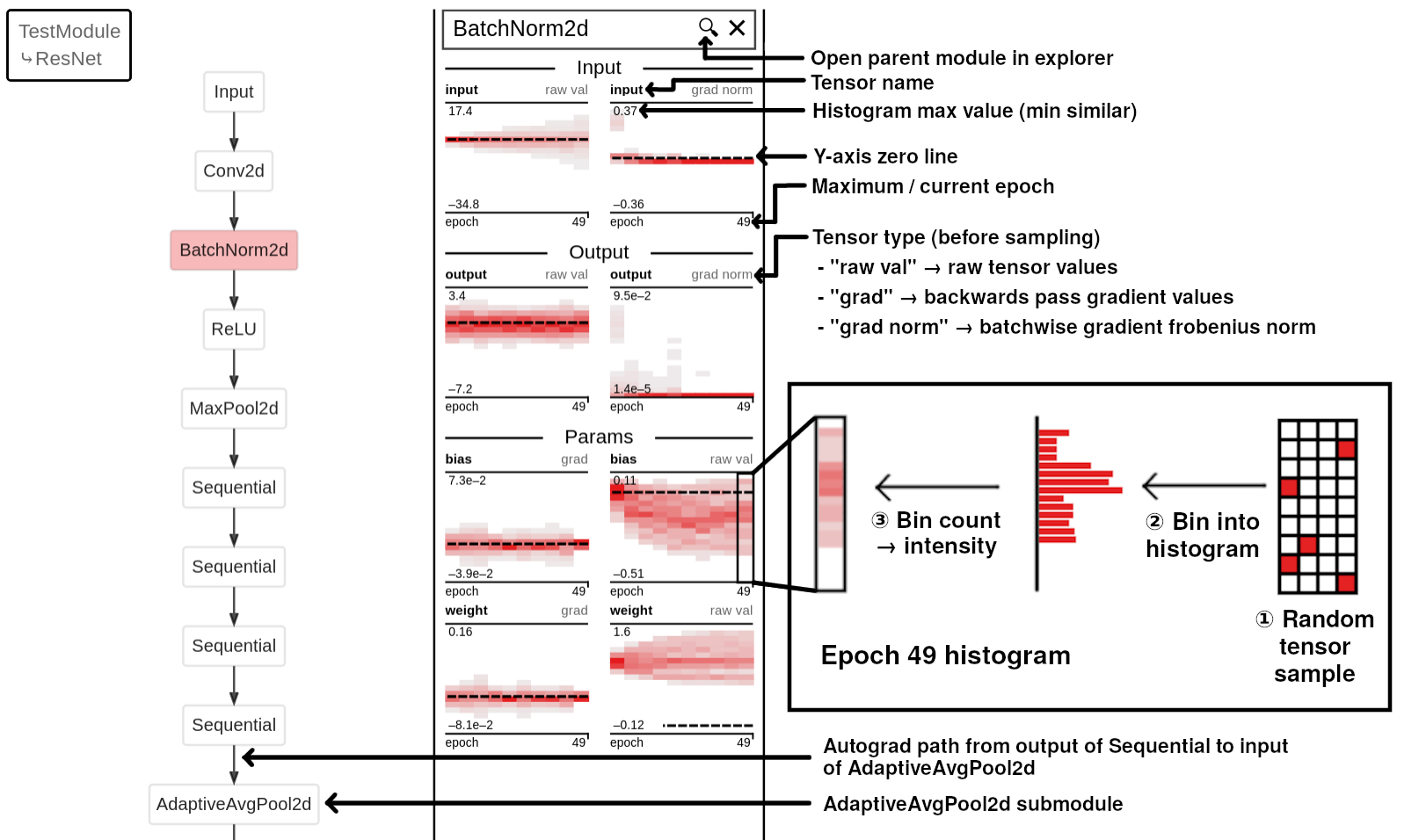
左侧面板包含网络架构的模块级图表,该图表是从自动微分图中自动提取的。点击模块将打开其"内部"子模块。要返回上级模块,请点击左上角展开列表中的相应元素。
节点。探索器图中的节点要么是a)可视化模块的输入/输出占位符,要么是b)可视化模块的特定子模块调用。如果可视化模块的forward函数有多个输入,这些输入将显示为多个节点("输入0"、"输入1"等)。输出也遵循类似的逻辑。所有其他节点代表一个不同的子模块调用。这意味着如果一个特定的子模块在一次前向传播中被调用两次,这两次调用在探索器图中会分别显示。它们的直方图和"内部"子模块也将是不同的。
边。两个节点之间的边意味着存在从父节点的某些输出到子节点的某些输入的自动微分跟踪。**节点的传入/传出边数与forward函数接受/产生的输入/输出数量无关。**为了说明这一点,让我们考虑一个有两个来自两个不同父节点的传入边的Linear节点。这可能是因为父模块的输出被加在一起,然后传递给单个forward函数输入。相反,考虑一个接受多个输入的TransformerEncoderLayer节点。如果TransformerEncoderLayer的所有输入都是从这个源计算得出的,那么可能仍然只有一个来自父模块的传入边。
工具提示。将鼠标悬停在探索器图节点上会显示有用的工具提示。前几行总结了输入/输出张量的形状,这些形状是从网络的第一次前向传播中记录的。随后的几行解析了module.extra_repr()中的关键信息。这种字符串解析是围绕常见的PyTorch extra_repr()实现(如nn.Conv2d)设计的。首先,字符串按逗号分割,每个结果字符串成为工具提示中的一行。如果结果子字符串的形式为"{key}={value}",这些将成为工具提示的键值对。否则,整个字符串将被视为一个值,键为空,用破折号可视化。这发生在Conv2d的in_channels和out_channels属性上。
面板
要更详细地检查模块,只需将其拖放到右侧的列中。直方图的颜色本身并不代表任何内在含义——它们只是帮助在探索器中识别正在可视化的模块。
直方图
直方图的每个垂直"切片"编码了相应x轴时间的值分布。y轴显示直方图的最小/最大边界。完全白色的方块意味着该bin中没有数据。只有一个条目的bin将被浅灰色着色,随着更多值落入该bin,颜色会变得更加强烈(这编码了直方图的"高度")。虚线水平线是$y=0$线。
[!注意] 填充直方图的张量以两种方式进行处理。首先,出于性能考虑,它们根据
sample_n参数进行随机子采样。默认值为100,传递None将禁用子采样。请注意,这种采样意味着应该相同的直方图可能看起来略有不同(例如,父节点的输出和子节点的输入)。其次,一定比例的离中值最远的值被拒绝,以防止异常值压缩直方图。这个比例默认为0.1,可以通过向reject_outlier_propertion参数传递0.0来禁用。
对于以下解释,我将参考这个模块:
class TestModule(nn.Module):
def __init__(self):
super().__init__()
self.fc = nn.Linear(20, 20)
self.activation = nn.ReLU()
def forward(self, x):
x1 = self.fc(x)
x2 = self.activation(x1)
return x2
输入/输出直方图。这些直方图表示传入和传出模块的forward方法的值,使用钩子捕获。例如,如果我们正在可视化上面TestModule中的fc层,input 0直方图将是x的直方图,output 0直方图将是x1的直方图。如果fc接受两个输入self.fc(x, y),那么直方图将显示input 0和input 1。请注意,activation模块的input 0直方图将与fc模块的output 0直方图非常接近,只是由于随机采样而有一些小的差异。
输入/输出梯度范数直方图。这些直方图捕获通过模块的backward传递的张量梯度。与参数梯度不同,我们在这里记录梯度的$\ell_2$-范数,在批次维度上取平均。这意味着如果损失相对于模块输入的梯度维度为$b \times d_1 \times d_2$,我们首先将其展平为$b \times (d_1 \cdot d_2)$向量,然后取行式范数得到长度为$b$的向量。这些值然后填充直方图。对于上面例子中的fc层,input 0 (grad norm)将这个程序应用于损失相对于x的梯度,而output 0 (grad norm)将这个程序应用于损失相对于y的梯度。
参数直方图。在提取输入/输出直方图后,所有子模块的直接参数(module._parameters)将被记录为直方图。请注意,这与module.parameters()不同,后者还会递归包含所有子参数。一些模块(特别是激活函数)没有参数,在界面中不会显示任何内容。例如,上面的TestModule没有可训练的直接参数;fc将有weight和bias参数;而activation再次没有任何参数。
参数梯度直方图。在完成backward调用后,每个参数将有一个.grad属性,存储损失相对于该参数的梯度。这个张量直接传递给直方图。与输入/输出梯度不同,不计算范数。
API
API文档可在这里查看。对于wandb训练,确保在wandb.init()之前调用torchexplorer.setup()。
特性和限制
一些特殊情况的注意事项。如果这里没有涉及到的内容,欢迎在GitHub上开issue。
支持的功能
- 支持多次调用同一模块。每次调用的输入/输出将分别显示,但参数和参数梯度当然是共享的。所以像这样的代码应该可以工作:
class TestModule(nn.Module):
def __init__(self):
super().__init__()
self.fc = nn.Linear(20, 20)
self.activation = nn.ReLU()
def forward(self, x):
x = self.activation(x)
x = self.fc(x)
x = self.activation(x)
return x
- 允许使用破坏自动求导图的不可微分操作,这不会导致崩溃。但是,生成的模块级图将相应地断开连接。
- 多个输入和输出将正确显示(即"输入0"、"输入1"等)
- 支持在单个步骤中多次调用
.forward()然后再进行反向传播,但必须传递delay_log_multibackward=True(默认禁用)。因此以下伪代码应该可以工作:
torchexplorer.watch(module, delay_log_multibackward=True)
# ...
# 在训练循环步骤中:
y_hat1 = module(X1)
y_hat2 = module(X2)
loss = (yhat1 - y1).abs().sum() + (yhat2 - y2).abs().sum()
loss.backward()
在界面中,您将看到多次调用的输入/输出直方图和输入/输出梯度直方图的叠加。
不支持
- 当模型处于
eval模式时,所有日志记录都被禁用,此状态下的任何forward调用都会被完全忽略。 - 不支持递归操作,任何在训练过程中动态改变模块级控制流的操作也不支持。例如,以下内容是不允许的:
if x > 0:
return self.module1(x)
else:
return self.module2(x)
- 不支持原地操作,应该进行修正或过滤(参见下面的"常见错误")。
- 不支持
forward方法的关键字张量参数。只会跟踪位置参数。目前尚未测试关键字张量参数的行为。 - 当在wandb的"Workspace"部分选择多个运行时,该工具无法使用。要检查模型,必须首先在wandb中打开要查看的特定运行。
- 未测试停止和恢复训练运行。
其他注意事项
- 调用模块时,不要使用
module.forward(x)方法。始终将前向方法调用为module(x)。前者不会调用torchexplorer使用的钩子。 - 直方图只会在_训练_期间更新,而不是在验证期间。这是直接通过
module.training进行检查的。这意味着如果您的验证数据集与训练数据集有不同的分布,您在工具中看到的可能无法反映验证期间的情况。
常见错误
本节包括一些我遇到的错误。对于这里未涵盖的内容,请随时在GitHub上提出问题。
1. 计算图中的原地操作
RuntimeError: Output 0 of BackwardHookFunctionBackward is a view and is being modified inplace...
这表明计算图中某处发生了原地操作,这会干扰输入/输出梯度捕获(io_grad)功能。这通常来自原地激活(例如nn.ReLU(inplace=True))或残差原地加法(例如out += identity)。如果您不关心梯度,可以在watch函数的log参数中省略'io_grad'。否则,还有两个额外的工具可用。您可以使用disable_inplace参数自动关闭所有激活的inplace标志。如果这还不够,您必须找出哪些子模块在进行原地操作,并手动修复它们或将这些类传递给ignore_io_grad_classes参数。例如,torchvision resnet实现中的BasicBlock有一个原地残差连接。resnet中的ReLU激活也设置了inplace=True。所以我们可以这样做:
model = torchvision.models.resnet18(pretrained=False)
watch(
model,
disable_inplace=True,
ignore_io_grad_classes=[torchvision.models.resnet.BasicBlock]
)
2. Weights and Biases图表故障
"No data available." 在自定义图表中。
这偶尔会在Weights and Biases界面中出现,似乎是他们自定义图表支持中难以复现的bug。有时等待可以解决问题。如果可能的话,当您注意到这个问题时,只需重新开始训练。另外,确保您的浏览器是最新版本。将Chrome更新到最新版本完全解决了我的这个问题。
"Something went wrong..." 并且Google Chrome崩溃。
在使用torchexplorer时,wandb网站偶尔会崩溃。重新加载页面似乎总能解决问题。同样,当我将Chrome更新到最新版本时,这个问题就完全解决了。
3. Graphviz溢出错误
在graphviz调用中出现"Trapezoid overflow"错误。
这是Graphviz 2.42.2中的已知bug,这个古老的版本仍然是大多数包管理器的默认版本。如果您遇到这个错误,可以通过安装较新版本来解决。
4. 打开的文件过多
OSError: [Errno 24] Too many open files: b'/proc'
...
wandb: WARNING Failed to cache... too many open files
这是wandb在上传大量表格时的已知bug。目前我唯一的解决方法是在调用wandb.init()之前调用torchexplorer.setup(),将ulimit从默认的1024修改为50000。您也可以尝试增加log_freq,以减少记录的表格数量。如果您仍然遇到问题,可能需要按照这里描述的编辑/etc/security/limits.conf。
相关工具
以下是一些相关工具的部分列表。第一部分涉及可视化模型结构,第二部分涉及在训练过程中可视化参数/激活。TorchExplorer以交互方式结合了这些功能。TorchExplorer的特点是只有在点击进入子模块时才显示嵌套的子模块,在我看来,这使界面更加整洁。
模型结构可视化。
参数/激活可视化。











