
 Github
Github 文档
文档 论文
论文PyTorch学习率查找器



这是Leslie N. Smith在《用于训练神经网络的循环学习率》中详细介绍的学习率范围测试的PyTorch实现,以及fastai使用的改进版本。
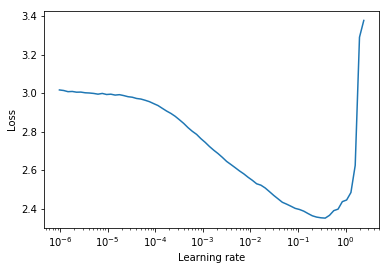
学习率范围测试是一种提供有关最佳学习率的宝贵信息的测试。在预训练运行期间,学习率在两个边界之间线性或指数增加。较低的初始学习率允许网络开始收敛,随着学习率的增加,最终会变得过大,导致网络发散。
通常,在下降的损失曲线中间可以找到一个良好的静态学习率。在下面的图中,这个值为lr = 0.002。
对于循环学习率(也在Leslie Smith的论文中详细介绍),学习率在两个边界(start_lr, end_lr)之间循环,作者建议将损失开始下降的点作为start_lr,将损失停止下降或变得不规则的点作为end_lr。在下面的图中,start_lr = 0.0002,end_lr=0.2。
安装
Python 3.5及以上版本:
pip install torch-lr-finder
安装支持混合精度训练的版本(详见此部分):
pip install torch-lr-finder -v --global-option="apex"
实现细节和使用方法
fastai的改进版本
以指数方式增加学习率,并计算每个学习率的训练损失。lr_finder.plot()绘制训练损失与对数学习率的关系图。
from torch_lr_finder import LRFinder
model = ...
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-7, weight_decay=1e-2)
lr_finder = LRFinder(model, optimizer, criterion, device="cuda")
lr_finder.range_test(trainloader, end_lr=100, num_iter=100)
lr_finder.plot() # 检查损失-学习率图
lr_finder.reset() # 将模型和优化器重置为初始状态
Leslie Smith的方法
线性增加学习率,并计算每个学习率的评估损失。lr_finder.plot()绘制评估损失与学习率的关系图。
这种方法通常可以产生更精确的曲线,因为评估损失对发散更敏感,但测试时间明显更长,尤其是在评估数据集较大的情况下。
from torch_lr_finder import LRFinder
model = ...
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.1, weight_decay=1e-2)
lr_finder = LRFinder(model, optimizer, criterion, device="cuda")
lr_finder.range_test(trainloader, val_loader=val_loader, end_lr=1, num_iter=100, step_mode="linear")
lr_finder.plot(log_lr=False)
lr_finder.reset()
注意事项
- examples文件夹中可以找到CIFAR10和MNIST的示例。
- 传递给
LRFinder的优化器不应附加LRScheduler。 LRFinder.range_test()会改变模型权重和优化器参数。可以通过LRFinder.reset()将两者恢复到初始状态。- 可以通过
lr_finder.history访问学习率和损失历史。这将返回一个包含lr和loss键的字典。 - 使用
step_mode="linear"时,学习率范围应在同一数量级内。 LRFinder.range_test()期望从传递给它的DataLoader对象返回一对input, label。input必须准备好传递给模型,label必须准备好传递给criterion,无需进行任何进一步的数据处理/处理/转换。如果您发现需要变通方法,可以使用TrainDataLoaderIter和ValDataLoaderIter类在DataLoader和训练/评估循环之间执行任何数据处理/处理/转换。您可以在examples/lrfinder_cifar10_dataloader_iter中找到如何使用这些类的示例。
额外的训练支持
梯度累积
您可以在LRFinder.range_test()中设置accumulation_steps参数为适当的值来执行梯度累积:
from torch.utils.data import DataLoader
from torch_lr_finder import LRFinder
desired_batch_size, real_batch_size = 32, 4
accumulation_steps = desired_batch_size // real_batch_size
dataset = ...
# 注意`DataLoader`使用的`batch_size`
trainloader = DataLoader(dataset, batch_size=real_batch_size, shuffle=True)
model = ...
criterion = ...
optimizer = ...
# (可选)使用此设置,将自动采用`amp.scale_loss()`
# model, optimizer = amp.initialize(model, optimizer, opt_level='O1')
lr_finder = LRFinder(model, optimizer, criterion, device="cuda")
lr_finder.range_test(trainloader, end_lr=10, num_iter=100, step_mode="exp", accumulation_steps=accumulation_steps)
lr_finder.plot()
lr_finder.reset()
混合精度训练
现在支持apex.amp和torch.amp,以下是示例:
-
使用
apex.amp:from torch_lr_finder import LRFinder from apex import amp # 在运行`LRFinder`之前添加此行 model, optimizer = amp.initialize(model, optimizer, opt_level='O1') lr_finder = LRFinder(model, optimizer, criterion, device='cuda', amp_backend='apex') lr_finder.range_test(trainloader, end_lr=10, num_iter=100, step_mode='exp') lr_finder.plot() lr_finder.reset() -
from torch_lr_finder import LRFinder amp_config = { 'device_type': 'cuda', 'dtype': torch.float16, } grad_scaler = torch.cuda.amp.GradScaler() lr_finder = LRFinder( model, optimizer, criterion, device='cuda', amp_backend='torch', amp_config=amp_config, grad_scaler=grad_scaler ) lr_finder.range_test(trainloader, end_lr=10, num_iter=100, step_mode='exp') lr_finder.plot() lr_finder.reset()
请注意,混合精度训练的好处需要具有张量核心的NVIDIA GPU(参见:NVIDIA/apex #297)
此外,您可以尝试设置torch.backends.cudnn.benchmark = True来提高训练速度。(但它可能不适用于某些情况,请自行承担风险)
贡献和拉取请求
欢迎所有贡献,但首先请查看CONTRIBUTING.md。











