
 Github
Github 文档
文档 论文
论文DeepSpeech2 语音识别




本项目基于 PaddlePaddle 的 DeepSpeech 项目开发,进行了较大修改,方便训练中文自定义数据集,同时也便于测试和使用。DeepSpeech2 是基于 PaddlePaddle 实现的端到端自动语音识别(ASR)引擎,其论文为《Baidu's Deep Speech 2 paper》。本项目还支持各种数据增强方法,以适应不同的使用场景。支持在 Windows、Linux 下训练和预测,支持 Nvidia Jetson 等开发板推理预测。该分支为新版本,如需使用旧版本,请查看 release/1.0 分支。
动态图版本使用更简单,支持 Deepspeech2、Conformer、Squeezeformer 模型:PPASR
本项目使用的环境:
- Python 3.7
- PaddlePaddle 2.2.0
- Windows 或 Ubuntu
更新记录
- 2021.11.26: 修复集束解码 bug。
- 2021.11.09: 提供 WenetSpeech 数据集制作脚本。
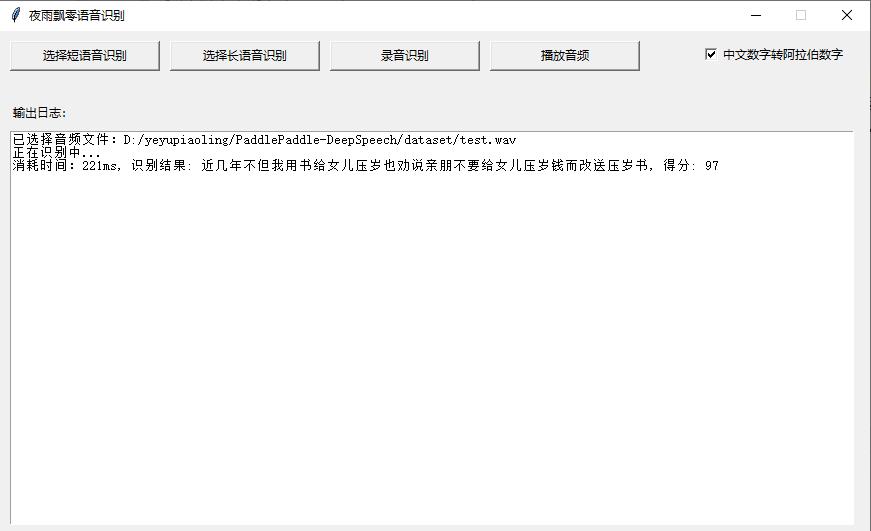
- 2021.09.05: 提供 GUI 界面识别部署。
- 2021.09.04: 提供三个公开数据的预训练模型。
- 2021.08.30: 支持中文数字转阿拉伯数字,具体请看预测文档。
- 2021.08.29: 完成训练代码和预测代码,同时完善相关文档。
- 2021.08.07: 支持导出预测模型,使用预测模型进行推理。使用 webrtcvad 工具,实现长语音识别。
- 2021.08.06: 将项目大部分代码修改为 PaddlePaddle 2.0 之后的新 API。
模型下载
| 数据集 | 卷积层数量 | 循环神经网络的数量 | 循环神经网络的大小 | 测试集字错率 | 下载地址 |
|---|---|---|---|---|---|
| aishell (179小时) | 2 | 3 | 1024 | 0.084532 | 点击下载 |
| free_st_chinese_mandarin_corpus (109小时) | 2 | 3 | 1024 | 0.170260 | 点击下载 |
| thchs_30 (34小时) | 2 | 3 | 1024 | 0.026838 | 点击下载 |
说明: 这里提供的是训练参数,如果要用于预测,还需要执行导出模型,使用的解码方法是集束搜索。
有问题欢迎提 issue 交流
文档教程
快速预测
python infer_path.py --wav_path=./dataset/test.wav
输出结果:
----------- 配置参数 -----------
alpha: 1.2
beam_size: 10
beta: 0.35
cutoff_prob: 1.0
cutoff_top_n: 40
decoding_method: ctc_greedy
enable_mkldnn: False
is_long_audio: False
lang_model_path: ./lm/zh_giga.no_cna_cmn.prune01244.klm
mean_std_path: ./dataset/mean_std.npz
model_dir: ./models/infer/
to_an: True
use_gpu: True
use_tensorrt: False
vocab_path: ./dataset/zh_vocab.txt
wav_path: ./dataset/test.wav
------------------------------------------------
消耗时间:132, 识别结果: 近几年不但我用书给女儿儿压岁也劝说亲朋不要给女儿压岁钱而改送压岁书, 得分: 94
- 长语音预测
python infer_path.py --wav_path=./dataset/test_vad.wav --is_long_audio=True
- Web部署
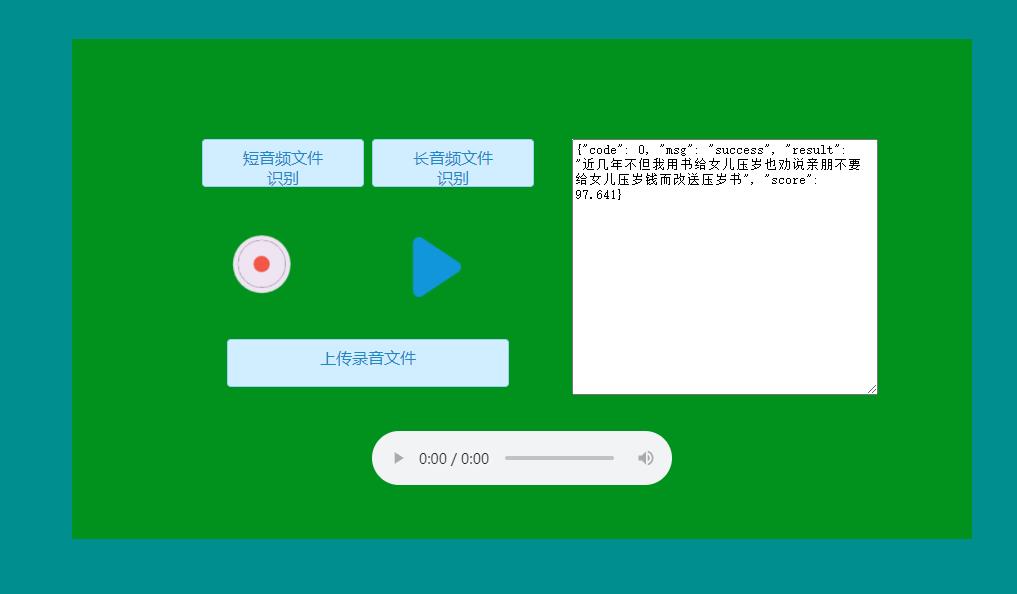
- GUI界面部署
打赏作者
打赏一块钱支持一下作者

相关项目
- 基于PaddlePaddle实现的声纹识别:VoiceprintRecognition-PaddlePaddle
- 基于PaddlePaddle动态图实现的语音识别:PPASR
- 基于Pytorch实现的语音识别:MASR











