
 Github
Github Huggingface
Huggingface 论文
论文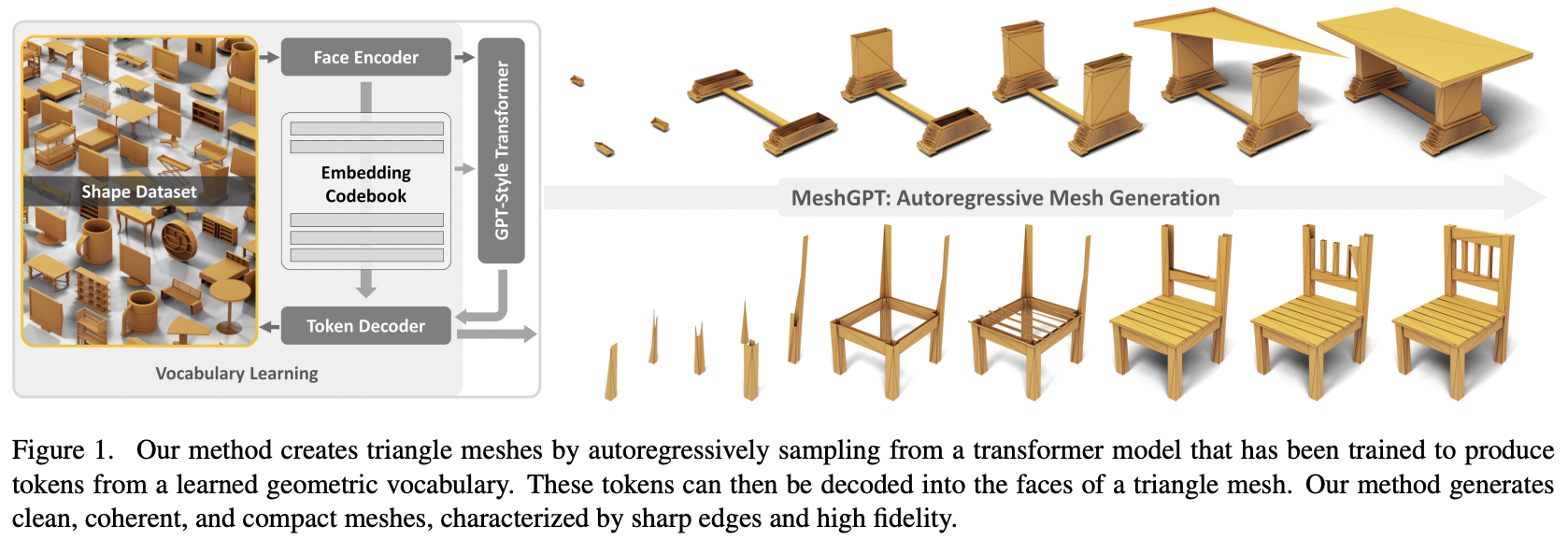
MeshGPT - Pytorch
在Pytorch中实现MeshGPT,使用注意力机制的最先进网格生成技术
还将添加文本条件,以实现最终的文本到3D资产转换
如果您有兴趣与他人合作复现这项工作,请加入

更新:Marcus已经训练并上传了一个可用模型到🤗 Huggingface!
致谢
-
感谢StabilityAI、A16Z开源AI资助计划和🤗 Huggingface的慷慨赞助,以及我的其他赞助者,让我能够独立开源当前的人工智能研究
-
感谢Einops让我的工作变得轻松
-
感谢Marcus进行初步代码审查(指出一些缺失的派生特征)以及运行首次成功的端到端实验
-
感谢Quexi Ma发现了自动eos处理的多个错误
-
感谢Yingtian发现了空间标签平滑的位置高斯模糊中的一个错误
安装
$ pip install meshgpt-pytorch
使用方法
import torch
from meshgpt_pytorch import (
MeshAutoencoder,
MeshTransformer
)
# 自动编码器
autoencoder = MeshAutoencoder(
num_discrete_coors = 128
)
# 模拟输入
vertices = torch.randn((2, 121, 3)) # (批次, 顶点数, 坐标 (3))
faces = torch.randint(0, 121, (2, 64, 3)) # (批次, 面数, 顶点 (3))
# 确保对于可变长度的网格,faces用"-1"填充
# 前向传播faces
loss = autoencoder(
vertices = vertices,
faces = faces
)
loss.backward()
# 经过大量训练后...
# 您可以将上面的原始face数据传入transformer,以建模这个面顶点序列
transformer = MeshTransformer(
autoencoder,
dim = 512,
max_seq_len = 768
)
loss = transformer(
vertices = vertices,
faces = faces
)
loss.backward()
# 在transformer经过大量训练后,您现在可以采样生成新的3D资产
faces_coordinates, face_mask = transformer.generate()
# (批次, 面数, 顶点 (3), 坐标 (3)), (批次, 面数)
# 现在对生成的3D资产进行后处理
对于基于文本条件的3D形状合成,只需在您的MeshTransformer上设置condition_on_text = True,然后将您的描述列表作为texts关键字参数传入
例如:
transformer = MeshTransformer(
autoencoder,
dim = 512,
max_seq_len = 768,
condition_on_text = True
)
loss = transformer(
vertices = vertices,
faces = faces,
texts = ['一把高脚椅', '一个小茶壶'],
)
loss.backward()
# 在transformer经过大量训练后,您现在可以基于文本条件采样生成新的3D资产
faces_coordinates, face_mask = transformer.generate(
texts = ['一张长桌'],
cond_scale = 3. # cond_scale > 1. 将启用无分类器引导 - 可以设置在3. - 10.之间的任何值
)
如果您想对网格进行标记化,以便在多模态transformer中使用,只需在自动编码器上调用.tokenize方法(或在自动编码器训练器实例上使用相同的方法来获取指数平滑模型)
mesh_token_ids = autoencoder.tokenize(
vertices = vertices,
faces = faces
)
# (批次, 面顶点数, 残差量化层)
类型检查
在项目根目录下运行
$ cp .env.sample .env
待办事项
-
自动编码器
- 使用torch geometric的encoder sageconv
- 正确处理填充的scatter mean,用于平均顶点并在解码器回收之前对顶点进行RVQ
- 完成解码器和重建损失 + 承诺损失
- 处理可变长度的面
- 添加使用残差LFQ的选项,这是最新的量化开发,可扩展代码利用率
- 在编码器和解码器中使用xcit线性注意力
- 找出如何直接从面和顶点自动推导
face_edges - 在sage卷积之前嵌入从顶点派生的任何值(面积、角度等)
- 在编码器中添加一个额外的图卷积阶段,其中顶点在聚合到面之前用其连接的顶点邻居进行丰富。设为可选
- 允许编码器对顶点进行噪声处理,使自动编码器具有一定的去噪能力。考虑在噪声级别变化时对解码器进行条件处理
-
transformer
- 在生成过程中正确屏蔽eos logit
- 确保它能训练
- 自动处理sos标记
- 如果传入序列长度或掩码,自动处理eos标记
- 处理可变长度的面
- 在前向传播中
- 在生成时,处理所有eos逻辑 + 将eos之后的所有内容替换为pad id
- 生成 + 缓存kv
-
使用hf accelerate的训练器包装器
- 自动编码器 - 处理ema
- transformer
-
使用自己的 CFG 库进行文本调节
-
完成初步文本调节
-
确保 CFG 库能够支持在条件缩放时向两个独立调用传递参数(以及聚合它们的输出)
-
完善神奇的数据集装饰器,看看能否将其移至 CFG 库
-
分层变换器(使用 RQ 变换器)
-
修复其他仓库中简单门控循环层的缓存
-
局部注意力
-
修复两阶段分层变换器的 kv 缓存 - 现在速度提升 7 倍,比原始非分层变换器更快
-
修复门控循环层的缓存
-
允许自定义细粒度和粗粒度注意力网络的模型维度
-
弄清楚自动编码器是否真的必要 - 确实必要,消融实验在论文中
- 当传入网格离散器时,可以注入带相对距离的界面间注意力
- 额外的嵌入(角度、面积、法线)也可以在粗粒度变换器注意力之前附加
-
提高变换器效率
- 可逆网络
-
推测解码选项
-
花一天时间完善文档
引用
[引用内容保持不变]











