
 访问官网
访问官网 Github
Github 论文
论文
这些烟花并不存在
视频扩散 - Pytorch
文本到视频生成,正在实现!官方项目页面
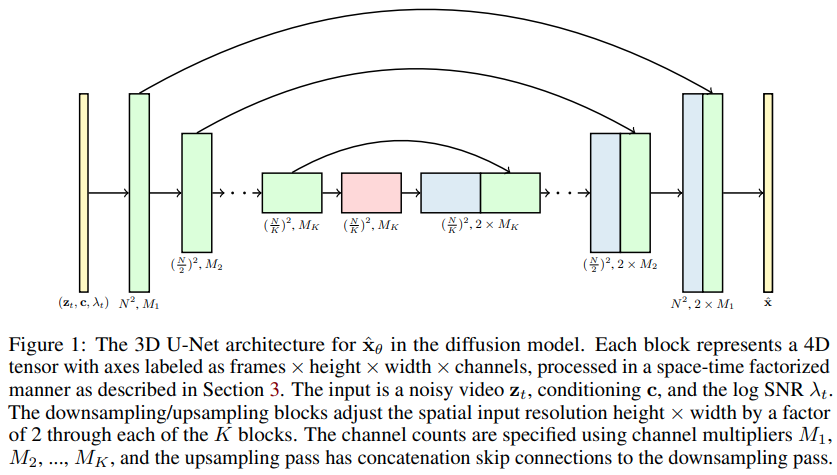
视频扩散模型的Pytorch实现,这是Jonathan Ho将DDPM扩展到视频生成的新论文。它使用了特殊的时空因子分解U-net,将生成从2D图像扩展到3D视频
当前状态
对于困难的移动MNIST数据集,14k步(收敛速度比NUWA快得多且效果更好)- 进行中

上述实验仅得益于Stability.ai提供的资源
文本到视频合成的任何新进展都将集中在Imagen-pytorch
安装
$ pip install video-diffusion-pytorch
使用方法
import torch
from video_diffusion_pytorch import Unet3D, GaussianDiffusion
model = Unet3D(
dim = 64,
dim_mults = (1, 2, 4, 8)
)
diffusion = GaussianDiffusion(
model,
image_size = 32,
num_frames = 5,
timesteps = 1000, # 步数
loss_type = 'l1' # L1或L2
)
videos = torch.randn(1, 3, 5, 32, 32) # 视频 (批次, 通道数, 帧数, 高度, 宽度) - 归一化到-1到+1
loss = diffusion(videos)
loss.backward()
# 经过大量训练后
sampled_videos = diffusion.sample(batch_size = 4)
sampled_videos.shape # (4, 3, 5, 32, 32)
对于文本条件,他们通过先将标记化的文本传入BERT-large来获得文本嵌入。然后你只需要这样训练:
import torch
from video_diffusion_pytorch import Unet3D, GaussianDiffusion
model = Unet3D(
dim = 64,
cond_dim = 64,
dim_mults = (1, 2, 4, 8)
)
diffusion = GaussianDiffusion(
model,
image_size = 32,
num_frames = 5,
timesteps = 1000, # 步数
loss_type = 'l1' # L1或L2
)
videos = torch.randn(2, 3, 5, 32, 32) # 视频 (批次, 通道数, 帧数, 高度, 宽度)
text = torch.randn(2, 64) # 假设BERT-large的输出维度为64
loss = diffusion(videos, cond = text)
loss.backward()
# 经过大量训练后
sampled_videos = diffusion.sample(cond = text)
sampled_videos.shape # (2, 3, 5, 32, 32)
如果你打算使用BERT-base进行文本条件,你也可以直接传入视频的描述字符串
import torch
from video_diffusion_pytorch import Unet3D, GaussianDiffusion
model = Unet3D(
dim = 64,
use_bert_text_cond = True, # 必须设置为True以自动使用bert模型维度
dim_mults = (1, 2, 4, 8),
)
diffusion = GaussianDiffusion(
model,
image_size = 32, # 帧的高度和宽度
num_frames = 5, # 视频帧数
timesteps = 1000, # 步数
loss_type = 'l1' # L1或L2
)
videos = torch.randn(3, 3, 5, 32, 32) # 视频 (批次, 通道数, 帧数, 高度, 宽度)
text = [
'远处一头鲸鱼跃出水面',
'小女孩正在吹灭生日蛋糕上的蜡烛',
'蓝色和绿色火花的烟花'
]
loss = diffusion(videos, cond = text)
loss.backward()
# 经过大量训练后
sampled_videos = diffusion.sample(cond = text, cond_scale = 2)
sampled_videos.shape # (3, 3, 5, 32, 32)
训练
这个仓库还包含一个方便的Trainer类,用于在包含gif文件的文件夹上进行训练。每个gif必须具有正确的image_size和num_frames尺寸。
import torch
from video_diffusion_pytorch import Unet3D, GaussianDiffusion, Trainer
model = Unet3D(
dim = 64,
dim_mults = (1, 2, 4, 8),
)
diffusion = GaussianDiffusion(
model,
image_size = 64,
num_frames = 10,
timesteps = 1000, # 步骤数
loss_type = 'l1' # L1或L2
).cuda()
trainer = Trainer(
diffusion,
'./data', # 该文件夹路径需包含所有训练数据,以.gif文件形式存储,图像大小和帧数正确
train_batch_size = 32,
train_lr = 1e-4,
save_and_sample_every = 1000,
train_num_steps = 700000, # 总训练步骤
gradient_accumulate_every = 2, # 梯度累积步骤
ema_decay = 0.995, # 指数移动平均衰减
amp = True # 启用混合精度
)
trainer.train()
示例视频(以gif文件形式)将定期保存到./results目录,扩散模型参数也会保存。
## 图像和视频的联合训练
论文中的一个观点是,通过进行因子化的时空注意力,可以强制网络在联合训练图像和视频时关注当前时刻,从而获得更好的结果。
他们如何实现这一点并不清楚,但我做了一个猜测。
要在训练过程中让一定比例的批次视频样本将注意力集中在当前时刻,只需在扩散前向方法中传入prob_focus_present = <prob>
loss = diffusion(videos, cond = text, prob_focus_present = 0.5) # 50%的视频在训练时聚焦当前
loss.backward()
如果你有更好的实现方法,请开一个GitHub issue。
## 待办事项
- [x] 连接文本条件,使用无分类器引导
- [x] 注意力中的相对位置编码(空间和时间)- 使用T5相对位置偏置而非他们使用的方法
- [x] 添加一个前向关键字参数,用于抑制跨时间的注意力(如论文所报告/声称,这种图像+视频同时训练的方式可以改善结果)
- [x] 考虑制作CLIP的3D版本,以便最终将DALL-E2的经验应用到视频中 https://github.com/lucidrains/dalle2-video
- [x] 为Trainer提供截短或填充帧的方法,以应对过长的gif
- [ ] 找到一个类似torchvideo的好库(torchvideo似乎不够成熟)用于烟花数据集的训练
- [ ] 将文本投影为4-8个标记,并将它们用作内存键/值来同时调节注意力块中的时间和空间
- [ ] 准备一个jax版本用于大规模TPU训练
- [ ] 让Trainer处理条件视频生成,文本作为相应的{video_filename}.txt存储在同一文件夹中
- [ ] 看看ffcv或squirrel-core是否适合
- [ ] 引入时间和空间的标记移位
## 引用
(引用内容保持原文)











