
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文X-Decoder: 像素、图像和语言的通用解码器
[项目主页] [论文] [HuggingFace 综合演示] [HuggingFace 指令演示] [视频]
作者:Xueyan Zou*, Zi-Yi Dou*, Jianwei Yang*, Zhe Gan, Linjie Li, Chunyuan Li, Xiyang Dai, Harkirat Behl, Jianfeng Wang, Lu Yuan, Nanyun Peng, Lijuan Wang, Yong Jae Lee^, Jianfeng Gao^ 发表于 CVPR 2023。
:hot_pepper: 快速开始
我们发布了 SEEM 和 X-Decoder 的以下内容:exclamation:
- 演示代码
- 模型检查点
- 全面的用户指南
- 训练代码
- 评估代码
:point_right: Linux 下 SEEM 演示一行命令:
git clone git@github.com:UX-Decoder/Segment-Everything-Everywhere-All-At-Once.git && sh aasets/scripts/run_demo.sh
:round_pushpin: [新] 入门指南:
:round_pushpin: [新] 最新检查点和数据:
| COCO | Ref-COCOg | VOC | SBD | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 方法 | 检查点 | 骨干网络 | PQ ↑ | mAP ↑ | mIoU ↑ | cIoU ↑ | mIoU ↑ | AP50 ↑ | NoC85 ↓ | NoC90 ↓ | NoC85 ↓ | NoC90 ↓ |
| X-Decoder | ckpt | Focal-T | 50.8 | 39.5 | 62.4 | 57.6 | 63.2 | 71.6 | - | - | - | - |
| X-Decoder-oq201 | ckpt | Focal-L | 56.5 | 46.7 | 67.2 | 62.8 | 67.5 | 76.3 | - | - | - | - |
| SEEM_v0 | ckpt | Focal-T | 50.6 | 39.4 | 60.9 | 58.5 | 63.5 | 71.6 | 3.54 | 4.59 | * | * |
| SEEM_v0 | - | Davit-d3 | 56.2 | 46.8 | 65.3 | 63.2 | 68.3 | 76.6 | 2.99 | 3.89 | 5.93 | 9.23 |
| SEEM_v0 | ckpt | Focal-L | 56.2 | 46.4 | 65.5 | 62.8 | 67.7 | 76.2 | 3.04 | 3.85 | * | * |
| SEEM_v1 | ckpt | Focal-T | 50.8 | 39.4 | 60.7 | 58.5 | 63.7 | 72.0 | 3.19 | 4.13 | * | * |
| SEEM_v1 | ckpt | SAM-ViT-B | 52.0 | 43.5 | 60.2 | 54.1 | 62.2 | 69.3 | 2.53 | 3.23 | * | * |
| SEEM_v1 | ckpt | SAM-ViT-L | 49.0 | 41.6 | 58.2 | 53.8 | 62.2 | 69.5 | 2.40 | 2.96 | * | * |
SEEM_v0: 支持单个交互对象的训练和推理
SEEM_v1: 支持多个交互对象的训练和推理
:fire: 新闻
- [2023.10.04] 我们很高兴发布 :white_check_mark: 训练/评估/演示代码、:white_check_mark: 新检查点和 :white_check_mark: 全面的说明文档,适用于 X-Decoder 和 SEEM!
- [2023.09.24] 我们提供了新的演示命令/代码用于推理 (DEMO.md)!
- [2023.07.19] :roller_coaster: 我们很高兴发布 X-Decoder 训练代码 (INSTALL.md、DATASET.md、TRAIN.md、EVALUATION.md)!
- [2023.07.10] 我们发布了 Semantic-SAM,这是一个通用图像分割模型,能够以任何所需的粒度对任何物体进行分割和识别。代码和检查点已经可用!
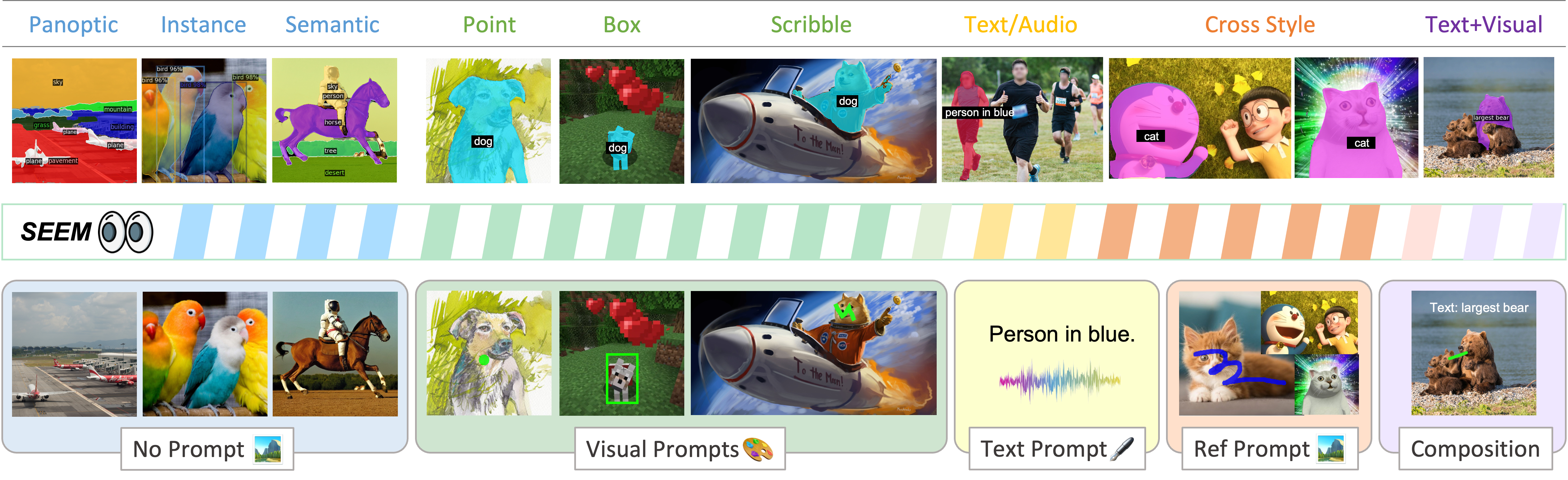
- [2023.04.14] 我们正在发布 SEEM,这是一个新的通用交互式图像分割接口!你可以将它用于任何分割任务,远远超出 X-Decoder 的能力范围!
- [2023.03.20] 作为我们 X-Decoder 的一个目标,我们开发了 OpenSeeD ([论文][代码]),以实现单一模型的开放词汇分割和检测,快来看看吧!
- [2023.03.14] 我们发布了 X-GPT,这是通过 GPT-3 langchain 实现的 X-Decoder 对话版本!
- [2023.03.01] 野外分割挑战赛已经启动,可以提交结果了!
- [2023.02.28] 我们发布了SGinW 基准测试,用于我们的挑战赛。欢迎在该基准上构建你自己的模型!
- [2023.02.27] 我们的 X-Decoder 已被 CVPR 2023 接收!
- [2023.02.07] 我们结合了 X-Decoder(强大的图像理解)、GPT-3(强大的语言理解)和 Stable Diffusion(强大的图像生成)制作了一个指令式图像编辑演示,快来看看吧!
- [2022.12.21] 我们发布了 X-Decoder 的推理代码。
- [2022.12.21] 我们发布了 Focal-T 预训练检查点。
- [2022.12.21] 我们发布了开放词汇分割基准测试。
:paintbrush: 演示
:blueberries: [X-GPT] :strawberry:[指令 X-Decoder]
:notes: 简介
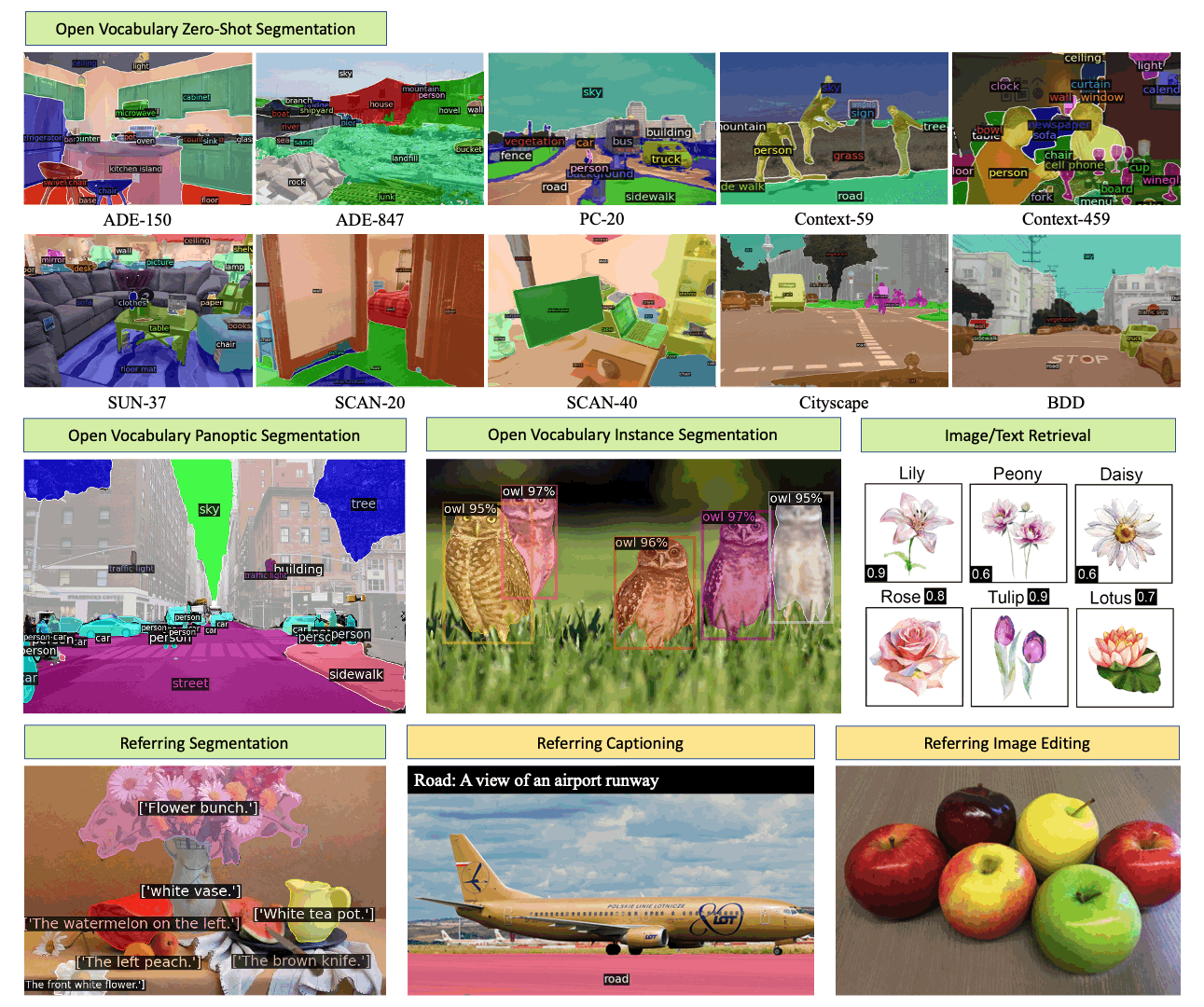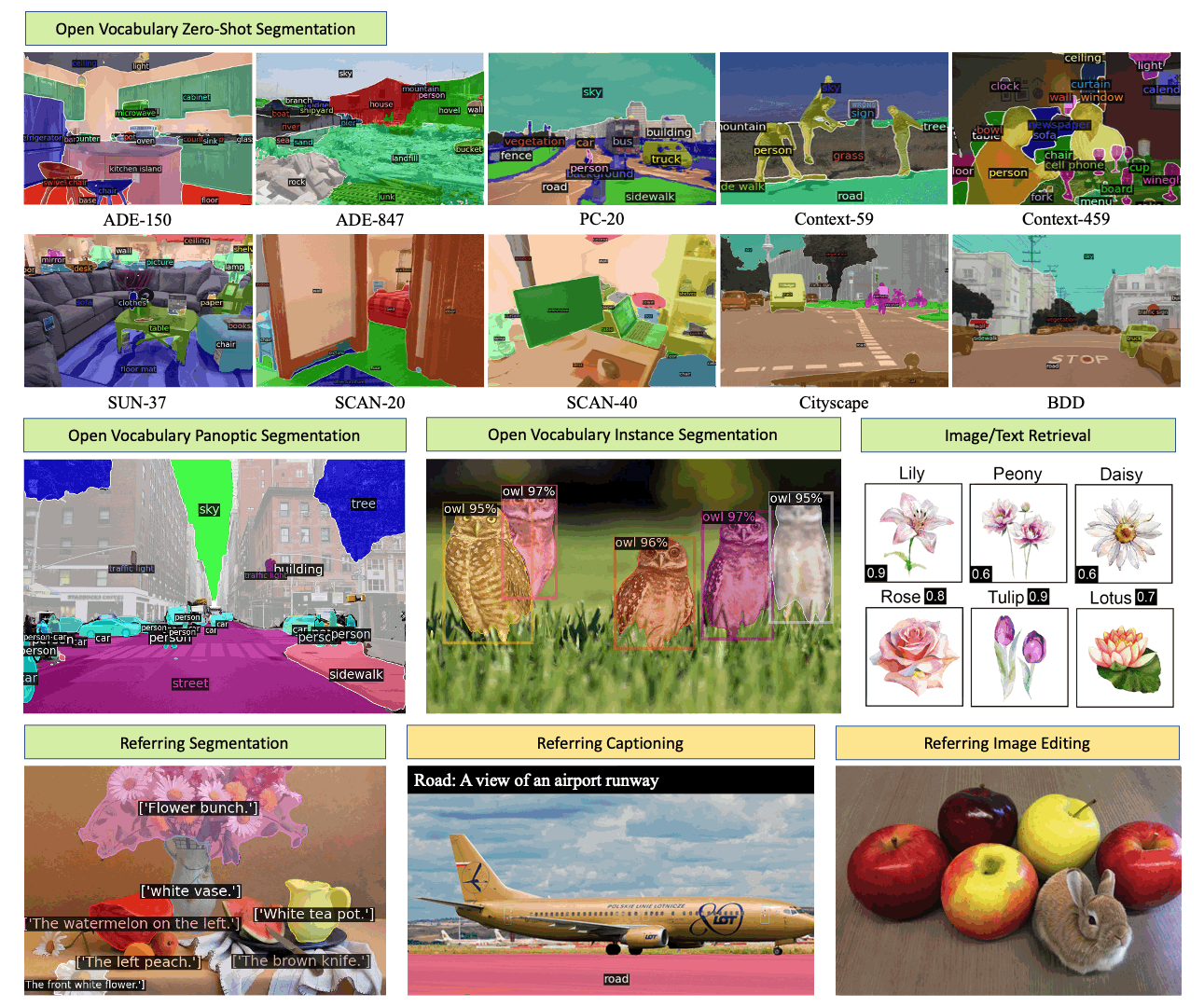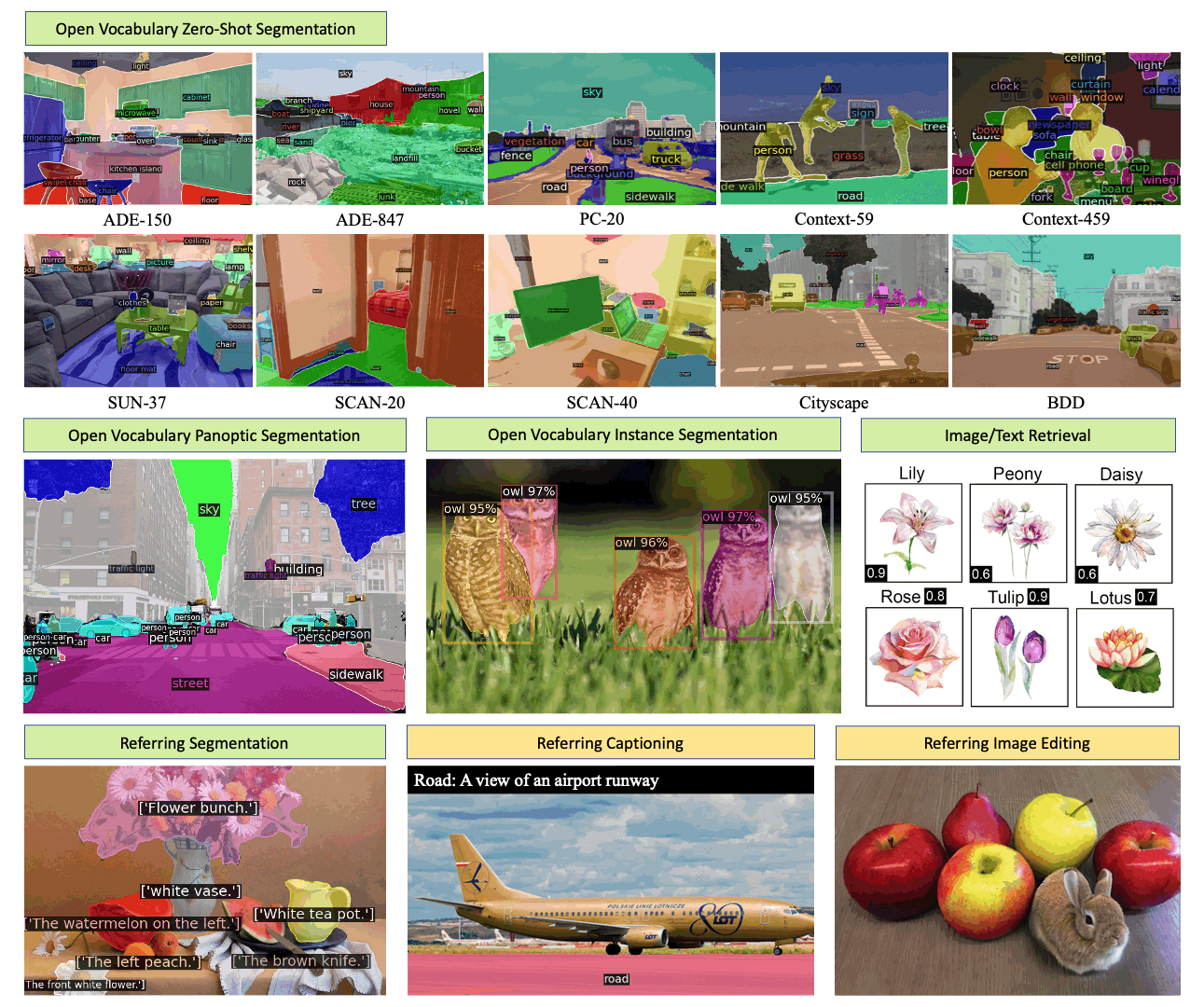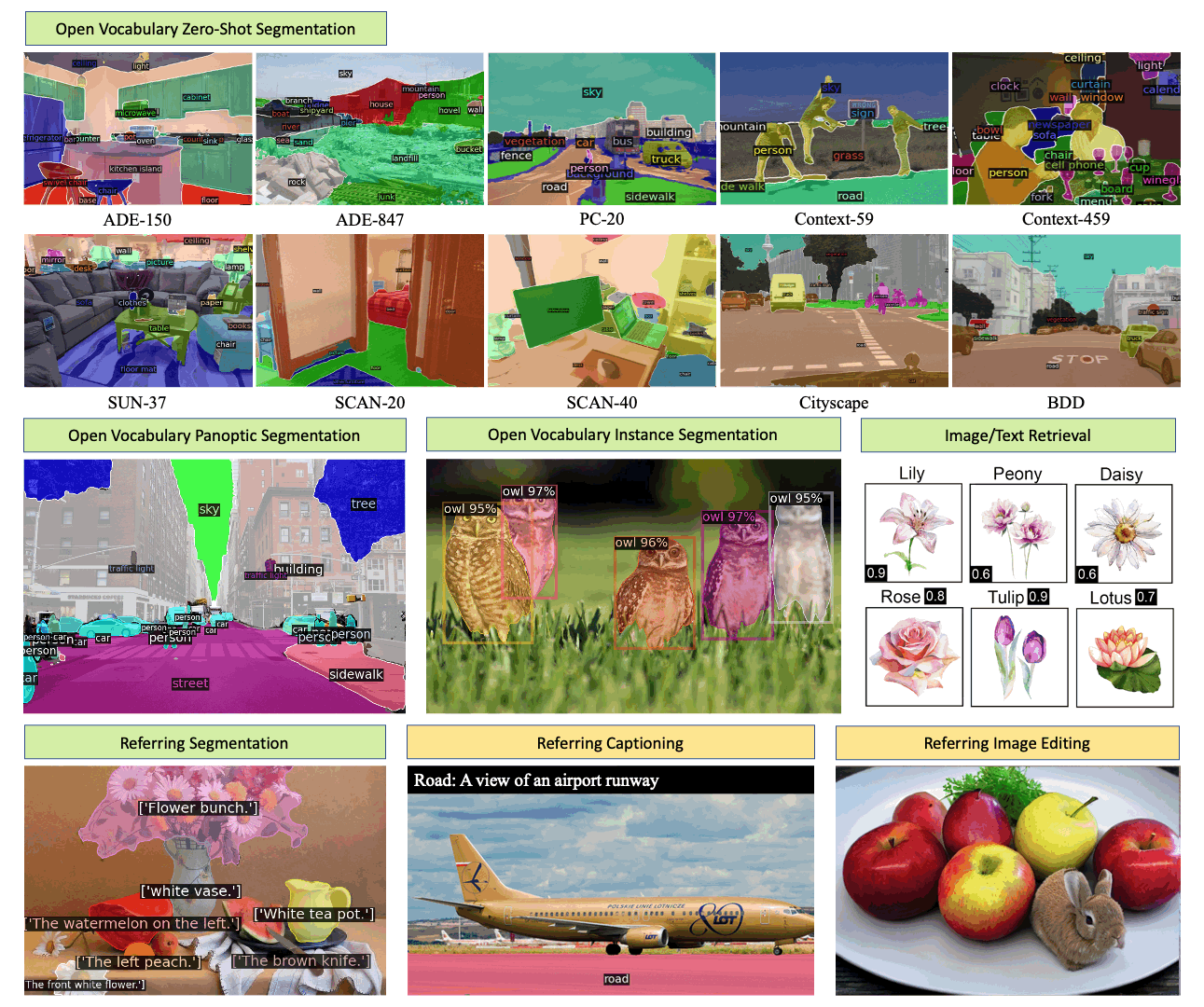
X-Decoder 是一个通用解码模型,可以无缝生成像素级分割和标记级文本!
它实现了:
- 在八个数据集上的开放词汇分割和指代分割方面取得了最先进的结果;
- 在分割和视觉语言任务上,经过微调后的性能优于或可与通用和专用模型相媲美;
- 适合高效微调,灵活应对新任务组合。
它支持:
- 一套参数预训练用于语义/实例/全景分割、指代分割、图像描述和图像-文本检索;
- 一个模型架构微调用于语义/实例/全景分割、指代分割、图像描述、图像-文本检索和视觉问答(带有额外的分类头);
- 零样本任务组合用于区域检索、指代描述、图像编辑。
安装
pip3 install torch==1.13.1 torchvision==0.14.1 --extra-index-url https://download.pytorch.org/whl/cu113
python -m pip install 'git+https://github.com/MaureenZOU/detectron2-xyz.git'
pip install git+https://github.com/cocodataset/panopticapi.git
python -m pip install -r requirements.txt
sh install_cococapeval.sh
export DATASET=/pth/to/dataset
这里是下载 coco_caption.zip 的新链接。
准备数据集请参考:DATASET.md
开放词汇分割
mpirun -n 8 python eval.py evaluate --conf_files configs/xdecoder/svlp_focalt_lang.yaml --overrides WEIGHT /pth/to/ckpt
注意:由于零填充,在单个 GPU 上填充多个图像可能会降低性能。
推理演示
# 对于分割任务
python demo/demo_semseg.py evaluate --conf_files configs/xdecoder/svlp_focalt_lang.yaml --overrides WEIGHT /pth/to/xdecoder_focalt_best_openseg.pt
# 对于视觉语言任务
python demo/demo_captioning.py evaluate --conf_files configs/xdecoder/svlp_focalt_lang.yaml --overrides WEIGHT /pth/to/xdecoder_focalt_last_novg.pt
模型库
| ADE | ADE-full | SUN | SCAN | SCAN40 | Cityscape | BDD | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 模型 | 检查点 | PQ | AP | mIoU | mIoU | mIoU | PQ | mIoU | mIoU | PQ | mAP | mIoU | PQ | mIoU |
| X-Decoder | BestSeg Tiny | 19.1 | 10.1 | 25.1 | 6.2 | 35.7 | 30.3 | 38.4 | 22.4 | 37.7 | 18.5 | 50.2 | 16.9 | 47.6 |
致谢
- 我们感谢与 Haotian Zhang 的建设性讨论
- 我们的工作基于 Mask2Former
- 我们的演示基于 HuggingFace :hugs: 提供的赞助 GPU
- 我们感谢在反驳阶段与 Xiaoyu Xiang 的讨论
引用
@article{zou2022xdecoder,
author = {Zou*, Xueyan and Dou*, Zi-Yi and Yang*, Jianwei and Gan, Zhe and Li, Linjie and Li, Chunyuan and Dai, Xiyang and Wang, Jianfeng and Yuan, Lu and Peng, Nanyun and Wang, Lijuan and Lee*, Yong Jae and Gao*, Jianfeng},
title = {Generalized Decoding for Pixel, Image and Language},
publisher = {arXiv},
year = {2022},
}











