
 访问官网
访问官网 Github
Github 文档
文档 论文
论文
AlphaTree : DNN && GAN && NLP && BIG DATA 从新手到深度学习应用工程师
从AI研究的角度来说,AI的学习和跟进是有偏向性的,更多的精英是擅长相关的一到两个领域,在这个领域做到更好。而从AI应用工程师的角度来说,每一个工程都可能涉及很多个AI的方向,而他们需要了解掌握不同的方向才能更好的开发和设计。
但是AI中每一个领域都在日新月异的成长。而每一位研究人员写paper的风格都不一样,相似的模型,为了突出不同的改进点,他们对模型的描述和图示都可能大不相同。为了帮助更多的人在不同领域能够快速跟进前沿技术,我们构建了“AlphaTree计划”,每一篇文章都会对应文章,代码,然后进行图示输出。
在面试到一些同学的时候,他们总是信誓旦旦的表示要转深度学习,但是存在能推导公式,但是一到深入理念,或者工程项目细节就两眼一抹黑。有没有一个项目,能一个一个项目帮助大家理解深度学习的发展同时也提高应用能力。
基于这种想法,邀请了几位资深程序员加入这个项目。希望丰富的资源能够帮助到大家。
版权申明:CC-BY-NC-SA 知识共享-署名-非商业性-相同方式共享
1 AI千集 www.aiqianji.com 以AI应用为目的 的一个社区。 ( AI+ Creation = Change the world。 AI千集在研究一些智能创作的事情,现在每天都会更新AI自己筛选的文章等等。 试试让AI 来服务于大家,)
公众号 千集技术

智能创作 主要各家gpt模型和接口都已经接入,用AI处理文字日常,已经到来。 AI绘图我们也做了很久,给to b训了很多独家模型。最近在研究to c一些有趣的玩法。
2 AIGC 导航网站 2022年被称为AIGC的元年,写作,绘画,音乐,日新月异。 这个由于更新迭代很快,因此将常用的软件做了导航。
3 AlphaCreation -之宝贝计划
小学生 关于AI的题目自用版
扫码打开:

知乎:点这里
微信: gingo_alphatree 邮箱: 5009024@qq.com

Sora 相关
https://github.com/hpcaitech/Open-Sora
https://github.com/lichao-sun/mora
经典部分
深度学习在解决分类问题上非常厉害。让它声名大噪的也是对于图像分类问题的解决。也产生了很多很经典的模型。其他方向的模型发展很多都是源于这部分,它是很多模型的基础工作。因此我们首先了解一下它们。

从模型的发展过程中,随着准确率的提高,网络结构也在不断的进行改进,现在主要是两个方向,一是深度,二是复杂度。此外还有卷积核的变换等等。
深度神经网络的发展要从经典的LeNet模型说起,那是1998年提出的一个模型,在手写数字识别上达到商用标准。之后神经网络的发展就由于硬件和数据的限制,调参的难度等各种因素进入沉寂期。
到了2012年,Alex Krizhevsky 设计了一个使用ReLu做激活函数的AlexNet 在当年的ImageNet图像分类竞赛中(ILSVRC 2012),以top-5错误率15.3%拿下第一。 他的top-5错误率比上一年的冠军下降了十个百分点,而且远远超过当年的第二名。而且网络针对多GPU训练进行了优化设计。从此开始了深度学习的黄金时代。
大家发表的paper一般可以分为两大类,一类是网络结构的改进,一类是训练过程的改进,如droppath,loss改进等。
之后网络结构设计发展主要有两条主线,一条是Inception系列(即上面说的复杂度),从GoogLeNet 到Inception V2 V3 V4,Inception ResNet。 Inception module模块在不断变化,一条是VGG系列(即深度),用简单的结构,尽可能的使得网络变得更深。从VGG 发展到ResNet ,再到DenseNet ,DPN等。
最终Google Brain用500块GPU训练出了比人类设计的网络结构更优的网络NASNet,最近训出了mNasNet。
此外,应用方面更注重的是,如何将模型设计得更小,这中间就涉及到很多卷积核的变换。这条路线则包括 SqueezeNet,MobileNet V1 V2 Xception shuffleNet等。
ResNet的变种ResNeXt 和SENet 都是从小模型的设计思路发展而来。
输入:图片 输出:类别标签

| 模型名 | AlexNet | ZFNet | VGG | GoogLeNet | ResNet |
|---|---|---|---|---|---|
| 初入江湖 | 2012 | 2013 | 2014 | 2014 | 2015 |
| 层数 | 8 | 8 | 19 | 22 | 152 |
| Top-5错误 | 16.4% | 11.2% | 7.3% | 6.7% | 3.57% |
| Data Augmentation | + | + | + | + | + |
| Inception(NIN) | - | - | - | + | - |
| 卷积层数 | 5 | 5 | 16 | 21 | 151 |
| 卷积核大小 | 11,5,3 | 7,5,3 | 3 | 7,1,3,5 | 7,1,3 |
| 全连接层数 | 3 | 3 | 3 | 1 | 1 |
| 全连接层大小 | 4096,4096,1000 | 4096,4096,1000 | 4096,4096,1000 | 1000 | 1000 |
| Dropout | + | + | + | + | + |
| Local Response Normalization | + | + | - | + | - |
| Batch Normalization | - | - | - | - | + |
ILSVRC2016 2016年的 ILSVRC,来自中国的团队大放异彩:
CUImage(商汤和港中文),Trimps-Soushen(公安部三所),CUvideo(商汤和港中文),HikVision(海康威视),SenseCUSceneParsing(商汤和香港城市大学),NUIST(南京信息工程大学)包揽了各个项目的冠军。
CUImage(商汤科技和港中文):目标检测第一; Trimps-Soushen(公安部三所):目标定位第一; CUvideo(商汤和港中文):视频中物体检测子项目第一; NUIST(南京信息工程大学):视频中的物体探测两个子项目第一; HikVision(海康威视):场景分类第一; SenseCUSceneParsing(商汤和港中文):场景分析第一。 其中,Trimps-Soushen 以 2.99% 的 Top-5 分类误差率和 7.71% 的定位误差率赢得了 ImageNet 分类任务的胜利。该团队使用了分类模型的集成(即 Inception、Inception-ResNet、ResNet 和宽度残差网络模块的平均结果)和基于标注的定位模型 Faster R-CNN 来完成任务。训练数据集有 1000 个类别共计 120 万的图像数据,分割的测试集还包括训练未见过的 10 万张测试图像。
ILSVRC 2017 Momenta 提出的SENet 获得了最后一届 ImageNet 2017 竞赛 Image Classification 任务的冠军, 2.251% Top-5 错误率
模型总览 <- 之前展示所有模型的主页挪到这里来了。点这里 点这里
模型索引:
| LeNet | AlexNet | GoogLeNet | Inception V3 | VGG | ResNet and ResNeXt |
| Inception-Resnet-V2 | DenseNet | DPN | PolyNet | SENet | NasNet |
深度学习应用
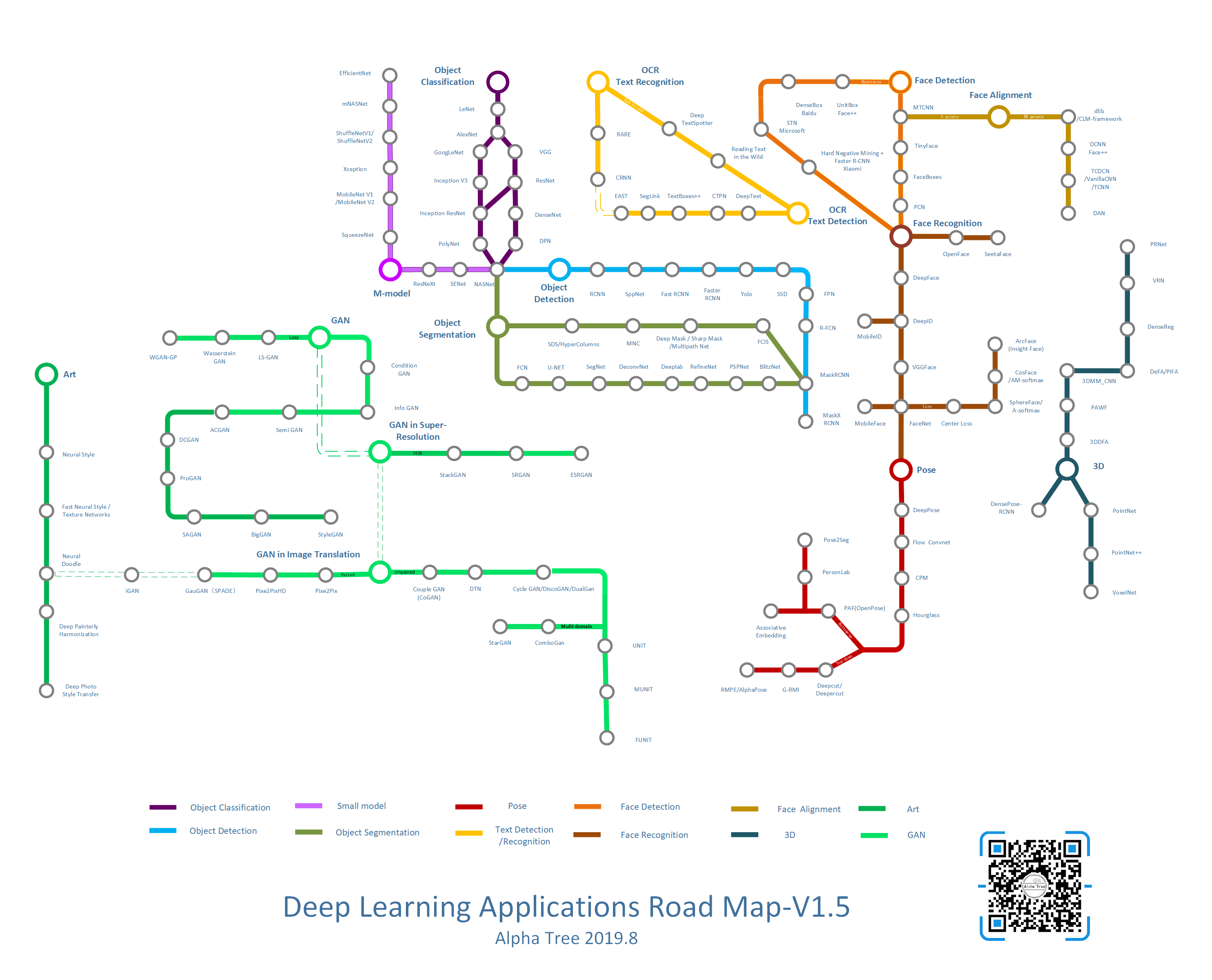
| 轻量级模型 & 剪枝 | 物体检测Object Detection | 物体分割Object Segmentation | OCR |
| 人脸检测Face Detection | 人脸识别Face Recognition | 肢体检测Pose Detection(coming soon) | 3D(coming soon) |
 物体分类(物体识别)解决的是这个东西是什么的问题(What)。而物体检测则是要解决这个东西是什么,具体位置在哪里(What and Where)。
物体分类(物体识别)解决的是这个东西是什么的问题(What)。而物体检测则是要解决这个东西是什么,具体位置在哪里(What and Where)。
物体分割则将物体和背景进行区分出来,譬如人群,物体分割中的实例分割则将人群中的每个人都分割出来。
输入: 图片 输出: 类别标签和bbox(x,y,w,h)

GAN基础

参考Mohammad KHalooei的教程,我也将GAN分为4个level,第四个level将按照应用层面进行拓展。这里基础部分包括Gan的定义,GAN训练上的改进,那些优秀的GAN。具体可以参见 GAN 对抗生成网络发展总览
GAN的定义 Level 0: Definition of GANs
| Level | Title | Co-authors | Publication | Links |
|---|---|---|---|---|
| Beginner | GAN : Generative Adversarial Nets | Goodfellow & et al. | NeurIPS (NIPS) 2014 | link |
| Beginner | GAN : Generative Adversarial Nets (Tutorial) | Goodfellow & et al. | NeurIPS (NIPS) 2016 Tutorial | link |
| Beginner | CGAN : Conditional Generative Adversarial Nets | Mirza & et al. | -- 2014 | link |
| Beginner | InfoGAN : Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets | Chen & et al. | NeuroIPS (NIPS) 2016 |
模型结构的发展:

GAN训练上的改进 Level1:Improvements of GANs training
然后看看 loss、参数、权重的改进:
| Level | Title | Co-authors | Publication | Links |
|---|---|---|---|---|
| Beginner | LSGAN : Least Squares Generative Adversarial Networks | Mao & et al. | ICCV 2017 | link |
| Advanced | Improved Techniques for Training GANs | Salimans & et al. | NeurIPS (NIPS) 2016 | link |
| Advanced | WGAN : Wasserstein GAN | Arjovsky & et al. | ICML 2017 | link |
| Advanced | WGAN-GP : improved Training of Wasserstein GANs | 2017 | link | |
| Advanced | Certifying Some Distributional Robustness with Principled Adversarial Training | Sinha & et al. | ICML 2018 | link code |
Loss Functions:
LSGAN(Least Squares Generative Adversarial Networks)
LS-GAN - Guo-Jun Qi, arxiv: 1701.06264
[2] Mao et al., 2017.4 pdf
https://github.com/hwalsuklee/tensorflow-generative-model-collections
https://github.com/guojunq/lsgan
用了最小二乘损失函数代替了GAN的损失函数,缓解了GAN训练不稳定和生成图像质量差多样性不足的问题。
但缺点也是明显的, LSGAN对离离群点的过度惩罚, 可能导致样本生成的'多样性'降低, 生成样本很可能只是对真实样本的简单模仿和细微改动。
WGAN
WGAN - Martin Arjovsky, arXiv:1701.07875v1
WGAN:
在初期一个优秀的GAN应用需要有良好的训练方法,否则可能由于神经网络模型的自由性而导致输出不理想。
为啥难训练? 令人拍案叫绝的Wasserstein GAN 中做了如下解释 :
原始GAN不稳定的原因就彻底清楚了:判别器训练得太好,生成器梯度消失,生成器loss降不下去;判别器训练得不好,生成器梯度不准,四处乱跑。只有判别器训练得不好不坏才行,但是这个火候又很难把握,甚至在同一轮训练的前后不同阶段这个火候都可能不一样,所以GAN才那么难训练。
https://zhuanlan.zhihu.com/p/25071913
WGAN 针对loss改进 只改了4点:
1.判别器最后一层去掉sigmoid
2.生成器和判别器的loss不取log
3.每次更新判别器的参数之后把它们的绝对值截断到不超过一个固定常数c
4.不要用基于动量的优化算法(包括momentum和Adam),推荐RMSProp,SGD也行
https://github.com/martinarjovsky/WassersteinGAN
WGAN-GP
Regularization and Normalization of the Discriminator:

WGAN-GP:
WGAN的作者Martin Arjovsky不久后就在reddit上表示他也意识到没能完全解决GAN训练稳定性,认为关键在于原设计中Lipschitz限制的施加方式不对,并在新论文中提出了相应的改进方案--WGAN-GP ,从weight clipping到gradient penalty,提出具有梯度惩罚的WGAN(WGAN with gradient penalty)替代WGAN判别器中权重剪枝的方法(Lipschitz限制):
[1704.00028] Gulrajani et al., 2017,improved Training of Wasserstein GANspdf
Tensorflow实现:https://github.com/igul222/improved_wgan_training
pytorch https://github.com/caogang/wgan-gp
GAN的实现 Level 2: Implementation skill
| 标题 | 合著者 | 发布 | 链接 | 大小 | FID/IS |
|---|---|---|---|---|---|
| GAN的Keras实现 | Linder-Norén | Github | 链接 | ||
| GAN实现技巧 | Salimans论文 & Chintala | 世界研究 | 链接 论文 | ||
| DCGAN: 用深度卷积生成对抗网络进行无监督表示学习 | Radford 等 | ICLR 2016 | 链接 论文 | 64x64 人类 | |
| ProGAN: 逐步增长的GAN以提高质量、稳定性和变化性 | Tero Karras | 2017 | 论文 链接 | 1024x1024 人类 | 8.04 |
| SAGAN:自注意生成对抗网络 | Han Zhang & Ian Goodfellow | 2018.05 | 论文 链接 | 128x128 物体 | 18.65/52.52 |
| BigGAN:大规模GAN训练以生成高保真自然图像 | Brock 等 | ICLR 2019 | 展示 论文 链接 | 512x512 物体 | 9.6/166.3 |
| StyleGAN:一种基于Style的生成对抗网络生成器架构 | Tero Karras | 2018 | 论文 链接 | 1024x1024 人类 | 4.04 |
指标:
1 生成质量分数 (IS,越大越好) IS用来衡量GAN网络的两个指标:1. 生成图片的质量 和2. 多样性
2 Fréchet生成质量距离 (FID,越小越好) 在FID中我们用相同的inception网络来提取中间层的特征。然后我们使用一个均值为 μμ 方差为 ΣΣ 的正态分布去模拟这些特征的分布。较低的FID意味着较高图片的质量和多样性。FID对模型坍塌更加敏感。
FID和IS都是基于特征提取,也就是依赖于某些特征的出现或者不出现。但是他们都无法描述这些特征的空间关系。
物体的数据在Imagenet数据库上比较,人脸的 progan 和stylegan 在CelebA-HQ和FFHQ上比较。上表列的为FFHQ指标。
具体可以参见 GAN 对抗生成网络发展总览
GAN的应用 Level 3: GANs应用
3-1 GANs 在计算机视觉中的应用
| 图像翻译 (Image Translation) | 超分辨率 (Super-Resolution) | 图像上色(Colourful Image Colorization) |
| 图像修复(Image Inpainting) | 图像去噪(Image denoising) | 交互式图像生成 |
特殊领域与应用
3-2 GANs在视频中的应用
3-3 GANs在NLP/语音中的应用
风格迁移
语音克隆 Voice Cloning
如何训练个性化语音
| 模型名 | 特点 | 文章名称 | 文章链接 | Github |
|---|---|---|---|---|
| WaveNet | 不是端到端的,输入并不是raw text而是经过处理的特征,代替了传统TTS pipeline的后端 | Wavenet:a generative model for raw audio | 链接 | |
| WaveRNN | 一般作为Tacotron的Vocoder来合成音频 | Efficient Neural Audio Synthesis | 链接 | |
| Tacotron | 第一个端对端的TTS神经网络模型 vocoder 需要改进 | 链接 | ||
| Tacotron 2 | https://github.com/NVIDIA/tacotron2 | |||
| 中文语音合成 | https://github.com/lturing/tacotronv2_wavernn_chinese | |||
| SV2TTS | Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis | https://github.com/CorentinJ/Real-Time-Voice-Cloning | ||
| 中文语音合成 | 链接 链接 |
NLP (即将到来)
大数据 (即将到来)
AIGC
stable diffusion
▶Automatic 1111:目前功能最完善最好用的stable diffusion网页版 网页链接
DreamBooth
▶DreamBooth:finetune(微调训练)自己的stable diffusion模型 网页链接
工具类
▶AdCreative.ai:专注于广告平面内容生成的AI 网页链接
▶AutoDraw:一个能够将你丑丑的简笔画自动平滑修复的网页工具 网页链接
▶Clip Interrogator:text to image的逆向工程——根据你上传的图片给出生成这个图片最可能的prompt引导词 网页链接
一树一获者,谷也;一树十获者,木也;一树百获者;人也。 希望我们每一个人的努力,能够建立一片森林,为后人投下一片树荫。
每一位加入的作者,都可以选取植物的名称来表示自己,然后logo和名字将会作为自己的署名。
我希望,这终将成为一片森林。
此外,关于深度学习系统中模型结构要怎样设计,特定的任务要不要加入特定的结构和方法,Yann LeCun 和 Christopher Manning 有一个讨论,大家可以看一看 https://youtu.be/fKk9KhGRBdI 雷锋网有介绍 https://www.leiphone.com/news/201804/6l2mAsZQCQG2qYbi.html











